动机
现代 GPU 加速器已经变得足够强大和功能丰富,能够执行通用计算 (GPGPU)。这是一个发展非常迅速的领域,吸引了大量开发计算密集型应用的科学家、研究人员和工程师的兴趣。尽管在 GPU 上重新实现算法存在困难,但许多人都在这样做,以检查它们的运行速度。为了支持这些努力,已经提供了许多高级语言和工具,例如 CUDA、OpenCL、C++ AMP、调试器、分析器等等。
计算机视觉的重要部分是图像处理,这是图形加速器最初设计的领域。其他部分也需要大规模并行计算,并且通常自然地映射到 GPU 架构。因此,在图形处理器上实现所有这些优势并加速 OpenCV 既具有挑战性,也极具意义。
历史
OpenCV 包括一个包含所有 GPU 加速内容的 GPU 模块。在 2010 年,NVIDIA 支持了该模块的工作,并在 2011 年春季的第一个版本之前启动。它包括对库的重要部分的加速代码,并且仍在不断发展,并正在适应新的计算技术和 GPU 架构。
目标
- 为开发人员提供一个方便的 GPU 上的计算机视觉框架,保持与当前 CPU 功能的概念一致性。
- 利用 GPU 实现最佳性能(针对现代架构调整的高效内核,优化数据流,如异步执行、复制重叠、零拷贝)
- 完整性(尽可能多地实现,即使加速效果不佳;这样可以完全在 GPU 上运行算法,并节省复制开销)
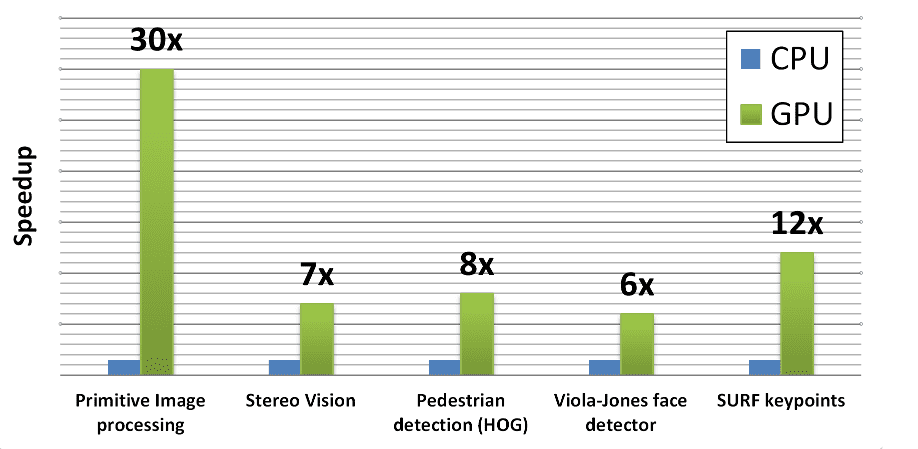
性能
Tesla C2050 与 Core i5-760 2.8Ghz、SSE、TBB
设计考虑因素
OpenCV GPU 模块使用 CUDA 编写,因此可以从 CUDA 生态系统中获益。有一个庞大的社区、会议、出版物、许多开发的工具和库,例如 NVIDIA NPP、CUFFT、Thrust。
GPU 模块被设计为主机 API 扩展。此设计允许用户明确控制如何在 CPU 和 GPU 内存之间移动数据。虽然用户必须编写一些额外的代码才能开始使用 GPU,但这两种方法都灵活且可以实现更有效的计算。
GPU 模块包含类 cv::gpu::GpuMat,它是存储在 GPU 内存中的数据的首要容器。它的接口与它的 CPU 对应部分 cv::Mat 非常相似。所有 GPU 函数都接收 GpuMat 作为输入和输出参数。这允许在不下载数据的情况下调用多个 GPU 算法。GPU 模块的 API 接口也尽可能地保持与 CPU 接口相似。因此,熟悉 CPU 上 OpenCV 的开发人员可以立即开始使用 GPU。
简短示例
在下面的示例中,图像从 png 文件加载,然后上传到 GPU,进行阈值处理,下载并显示。
#include <iostream>
#include "opencv2/opencv.hpp"
#include "opencv2/gpu/gpu.hpp"
int main (int argc, char* argv[])
{
try
{
cv::Mat src_host = cv::imread("file.png", CV_LOAD_IMAGE_GRAYSCALE);
cv::gpu::GpuMat dst, src;
src.upload(src_host);
cv::gpu::threshold(src, dst, 128.0, 255.0, CV_THRESH_BINARY);
cv::Mat result_host;
dst.download(result_host);
cv::imshow("Result", result_host);
cv::waitKey();
}
catch(const cv::Exception& ex)
{
std::cout << "Error: " << ex.what() << std::endl;
}
return 0;
}