

关于作者:
Siddharth Advani 于 2005 年获得印度浦那大学电子工程学士学位,2009 年获得宾夕法尼亚州立大学州学院电气工程硕士学位,2016 年获得该校计算机科学与工程博士学位。他的研究兴趣包括面向特定领域应用的实时嵌入式系统。他目前是三星美国研发中心的高级硬件工程师。这项工作是他攻读宾夕法尼亚州立大学博士学位期间完成的。
视觉搜索已成为当今计算系统上运行的许多多媒体应用程序的必要条件。诸如识别图像中场景的各个部分、检测零售店中的物品、导航自主无人机等任务与当今瞬息万变的环境密切相关。这些任务中的许多底层功能依赖于用于捕获基于光强度的数据的高分辨率相机传感器。然后,数据由不同的算法处理以执行诸如目标检测、目标识别、图像分割等任务。

视觉注意力在过去几年中在计算神经科学研究中获得了很大的关注。各种计算模型使用低级特征来构建信息图,然后将这些信息图融合在一起,形成通常称为显著性图的内容。给定要观察的图像,此显著性图本质上提供了图像中最重要的内容的紧凑表示。然后,该图可以用作一种机制,放大识别图像中最重要区域(RoI)的区域。例如,在图 1 中,不同的显著性模型显示了表示骑自行车者的像素在与背景形成鲜明对比的程度上。
这些模型假设人眼在其整个视野(FOV)中使用其全分辨率。然而,分辨率从中央凹点向周边下降,人类视觉系统 (HVS) 擅长注视,以便在注意力被吸引到该方向时调查周边区域。换句话说,我们的眼睛注视以允许兴趣点落在中央凹点上,中央凹点是最高分辨率的区域。只有在注视过程之后,我们才能从吸引我们注意力的感兴趣对象那里收集完整的信息。因此,HVS 的构建方式使得必须移动眼睛才能促进处理周围环境中的所有信息。正是由于这个原因,人类倾向于比远处目标更频繁地选择附近的位置,并且需要考虑这一点来计算显著性图,以提高模型的预测能力。了解我们眼睛有效地获取相关信息以执行不同任务的效率对构建下一代自主系统具有重大影响。构建注视框架以测试和改进用于实时自主导航的显著性模型是这项工作的重点。
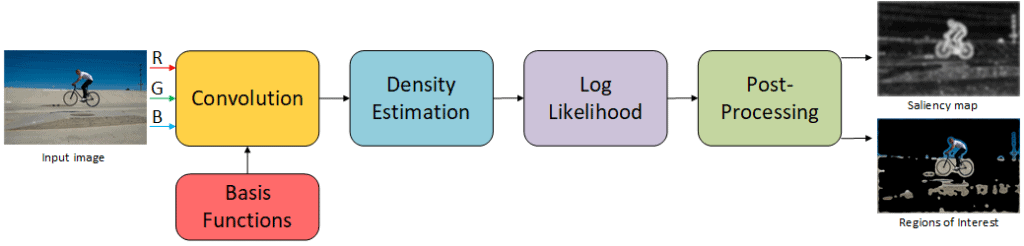
我们选择基于信息最大化的注意力 (AIM) 作为一种信息论计算显著性模型,作为我们注视框架的构建块。AIM 已针对许多其他显著性模型进行了基准测试,并且已被证明非常接近人类注视点。该模型试图使用香农的自信息理论将视觉内容计算为意外性或稀有性的度量。该算法分为三个主要部分,如图 2 所示。第一部分涉及通过将图像投影到一组学习到的基函数上来创建图像的稀疏表示。下一部分涉及使用直方图反投影技术进行密度估计。最后计算对数似然以给出最终的信息图。有关算法和其背后理论的更多详细信息,请参见 [1]。

为了模拟从中央凹点到周边分辨率的急剧下降,一旦图像被相机传感器捕获,我们就构建一个三级高斯金字塔,如图 3 所示。为此,我们首先从第 1 层提取 50% 的高分辨率中心区域作为我们的中央凹点。经过模糊和下采样后,从第 2 层裁剪出第二个区域,表示中等分辨率区域。另一轮模糊和下采样使我们获得了整个 FOV,但分辨率低得多(第 3 层)。需要注意的是,随着分辨率的下降,FOV 在我们的框架中逐渐增大。
在我们的实验中,我们使用了具有 1.4 毫米焦距和 185° 视野 (FOV) 的 ½ 英寸格式 C 型接口鱼眼镜头。捕获的图像大小为 1920×1920。随着人们远离中心,图像具有一些固有的非线性,这类似于人眼感知周围世界的方式。我们在这三个区域中的每一个区域上运行 AIM,这会返回相应的信息图。这些信息图表示不同分辨率下的显著区域,如图 4 (c) 所示。有多种方法可以融合这些信息图以给出最终的多分辨率显著性图。我们认为,每个图上的自适应加权函数将是动态环境中一个有价值的参数进行调整。但是,对于这项专注于静态图像的工作,我们分别对高分辨率中央凹点、中等分辨率区域和低分辨率区域使用权重 w1 = 1/3、w2 = 2/3 和 w3 = 1。我们使用这些权重是因为中央凹点中的像素在金字塔中出现三次,而中等分辨率区域中的像素出现两次。因此,这些权重可以防止最终的显著性图过度偏向中心。由于这些图的大小不同,因此在将它们加起来之前,会对其进行适当的上采样和零填充。

(a)输入图像(b)具有越来越大 FOV 的图像金字塔(c)视觉注意力显著性图(d)通过使用不同的权重融合(c)获得的多分辨率注意力图
为了验证我们的模型(称为多分辨率 AIM (MR-AIM)),我们对一系列模式运行了实验,如图 5 所示。首先,我们考虑了一系列在黑色背景上具有相同尺寸的空间分布的红点(图 5 (a) 和 5 (b))。从显著性结果(图 5 (e) 和 5 (f))中可以看出,随着人们远离中央凹点,显著性逐渐降低(红色对应于更高显著性的区域,而蓝色对应于较低显著性的区域)。
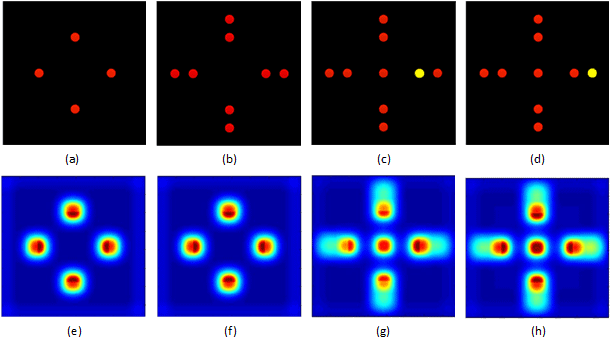
(a)-(d)输入图像,(e)-(h)显著性结果
起始被认为是在动态环境中驱动视觉注意力的,因此在图 5(c) 中,我们接下来考虑了感兴趣的新对象在中央凹点(红点)和周边(黄点)内到达的情况。在黄点周围区域获得了最大响应(图 5 (g))。接下来,我们考虑将黄点进一步移离中央凹点(图 5 (d))。同样,我们注意到显著性略有偏移,将注意力转移到中心(图 5 (h))。这些实验为我们提供了有关模型机制的有价值的信息,当感兴趣的对象相对于中央凹点移动时。



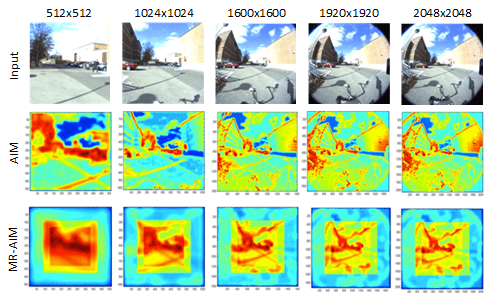
我们的下一组实验是将多分辨率模型与原始 AIM 模型进行比较,并从质量和性能方面对前者进行评估。这里应该注意的是,[4] 中提供的数据集中的图像最大尺寸为 1024×768,而此处设计的框架理想情况下针对包含大量显著对象的高分辨率图像。图 6(第 1 行)显示了一个此类图像的示例,从左到右尺寸逐渐增大。第 2 行描绘了原始 AIM 模型的结果。第 3 行显示了 MR-AIM 的输出。对于较小的图像尺寸,AIM 在发现主要 RoI 方面做得非常好。但是,随着图像尺寸开始增大,它开始将边缘作为最显著的特征。这是由于所用基内核的有限大小(21×21)造成的。增加内核的大小对于实时系统来说不是一个可行的选择,因为这反过来会增加计算时间。MR-AIM 没有这样的问题。由于它在不同分辨率下对较小的图像尺寸进行操作,因此可以检测不同尺度的对象。对象存在偏向中心的趋势,但权重在捕获周边区域的 RoI 方面也发挥了重要作用。这里应该注意的是,MR-AIM 不会拾取在周边变得极其显著的对象,但添加其他显著性通道(例如运动)将使模型在动态环境中更加稳健。

我们进行的另一组实验是在一系列视频帧上进行的,这些视频帧是在周围环境中捕获的,周围环境中存在足够的周边活动来激活注意力,如图 7 所示。我们比较了我们的模型与其他模型,而不是根据实际的眼动追踪数据进行验证,因为此类数据对于高清图像来说并不容易获得。顶行显示了 Itti 模型在第 17、22 和 27 帧的结果。中间行显示了 AIM 模型在相应帧的结果,而底行显示了 MR-AIM 的响应。为了进行公平的比较,我们停用了 Itti 模型中的返回抑制。AIM 和 MR-AIM 都相继捕获了第 22 帧中骑自行车的人的出现。这些实验使我们对所提议模型的定性性能充满信心。MR-AIM 也在 MIT 显着性数据集上进行了基准测试,详细结果可以在这里找到。我们的工作发表在 [5] 中,并且还提供了一个基于 OpenCV 的源代码在这里。
参考文献
[1] N. D. B. Bruce 和 J. K. Tsotsos,“基于信息最大化的显着性,”神经信息处理系统进展,第 18 卷,第 155-162 页,2006 年。
[2] L. Itti、C. Koch 和 E. Niebur,“用于快速场景分析的基于显着性的视觉注意模型,”IEEE 模式分析与机器智能汇刊,第 20 卷,第 11 期,第 1254-1259 页,1998 年。
[3] T. Judd、K. Ehinger、F. Durand 和 A. Torralba,“学习预测人类注视的位置”,IEEE 国际计算机视觉会议 (ICCV),2009 年。
[4] T. Judd、F. Durand 和 A. Torralba,“显着性计算模型预测人类注视点的基准,”2012 年。
[5] S. Advani、J. Sustersic、K. Irick 和 V. Narayanan,“一种多分辨率显着性框架来驱动注视点转移,”IEEE 第 38 届国际声学、语音和信号处理会议论文集,2013 年。


