
计算机视觉的进步,一个将机器学习与计算机科学融合的领域,通过深度学习的出现得到了显著提升。这篇关于计算机视觉的深度学习的文章探讨了从传统计算机视觉方法到深度学习创新高度的转型之旅。
我们首先概述阈值化和边缘检测等基础技术,以及 OpenCV 在传统方法中的关键作用。
传统计算机视觉的简史与演变
计算机视觉,一个位于交叉点机器学习和计算机科学的领域,其根源可以追溯到 20 世纪 60 年代,当时研究人员首次尝试使计算机能够解释视觉数据。从简单的任务,如区分形状,到更复杂的功能,这一旅程开始了。关键里程碑包括 20 世纪 70 年代初为数字图像处理开发的第一个算法,以及随后特征检测方法的演变。这些早期进步为现代计算机视觉奠定了基础,使计算机能够执行从目标检测到复杂场景理解的各种任务。
传统计算机视觉中的核心技术
阈值化:这项技术是图像处理和分割的基础。它涉及将灰度图像转换为二进制图像,其中像素根据阈值被标记为前景或背景。例如,在一个基本的应用中,阈值化可以用来区分黑白图像中一个物体与其背景。
边缘检测:边缘检测算法(如 Canny 边缘检测器)在特征检测和图像分析中至关重要,它可以识别图像中物体的边界。通过检测亮度的不连续性,这些算法有助于理解图像中各种物体的形状和位置,为更高级的分析奠定了基础。
在这里可以找到来自 OpenCV 大学的顶级计算机视觉和深度学习课程列表。
OpenCV 的主导地位
OpenCV(开源计算机视觉库)是计算机视觉领域的关键参与者,自 20 世纪 90 年代后期以来,它提供了超过 2500 种经过优化的算法。它易于使用且在人脸识别和交通监控等任务中的多功能性使其成为学术界和行业,尤其是实时应用中的最爱。
随着深度学习的出现,计算机视觉领域发生了显著的演变,从传统的基于规则的方法转变为更先进、更适应性的系统。早期的技术,如阈值化和边缘检测,在复杂场景中存在局限性。深度学习,尤其是卷积神经网络 (CNN),通过直接从数据中学习来克服这些局限性,从而实现更准确、更通用的图像识别和分类。
这种进步,由计算能力的提高和大型数据集的驱动,导致了自动驾驶和医学影像等领域的重大突破,使深度学习成为现代计算机视觉的一个基本方面。
深度学习模型
用于图像分类的 ResNet-50
ResNet-50 是 ResNet(残差网络)模型的变体,ResNet 在计算机视觉的深度学习领域取得了突破,尤其是在图像分类任务中。ResNet-50 中的“50”指的是网络中的层数 - 它包含 50 层深,与之前的模型相比有了显著的提升。
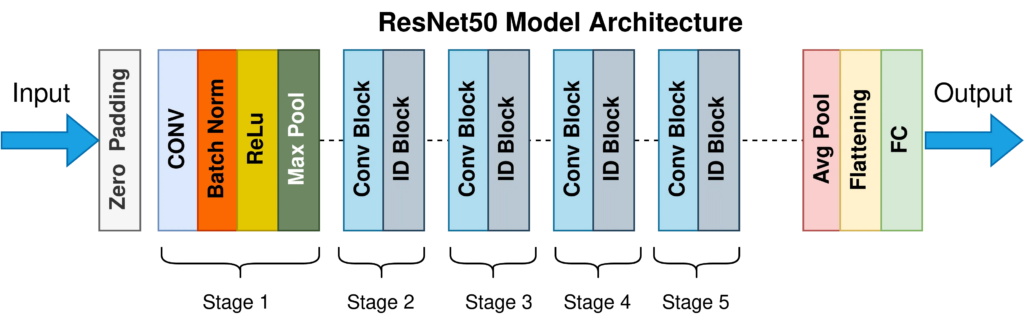
ResNet-50 的关键特性
1. 残差块:ResNet-50 背后的核心思想是使用残差块。这些块允许模型通过所谓的“跳跃连接”或“捷径连接”跳过一层或多层。这种设计解决了梯度消失问题,这是深度网络中常见的问题,其中梯度在反向传播到层时会越来越小,这使得训练非常深的网络变得困难。
2. 改进的训练:由于这些残差块,ResNet-50 可以训练得更深,而不会受到梯度消失问题的困扰。这种深度使网络能够在不同级别学习更复杂的特征,这是其在图像分类任务中性能提升的关键因素。
3. 通用性和效率:尽管深度很大,但与其他深度模型相比,ResNet-50 在计算资源方面仍然相对高效。它在 ImageNet 等各种图像分类基准测试中取得了优异的准确率,使其成为研究界和行业中广受欢迎的选择。
4. 应用:ResNet-50 已广泛应用于各种现实世界应用中。它能够将图像分类为数千个类别,使其适用于自动驾驶中的目标识别、社交媒体平台中的内容分类,以及通过分析医疗图像来帮助医疗保健中的诊断程序。
对计算机视觉的影响
ResNet-50 显著地推动了图像分类领域的发展。其架构为深度学习和计算机视觉中的许多后续创新奠定了基础。通过使更深的神经网络的训练成为可能,ResNet-50 为计算机视觉系统能够处理的任务的准确性和复杂性开辟了新的可能性。
YOLO(你只看一次)模型
该YOLO (你只看一次)模型是计算机视觉领域的一项革命性方法,尤其是在目标检测任务中。YOLO 以其速度和效率而著称,使实时目标检测成为现实。
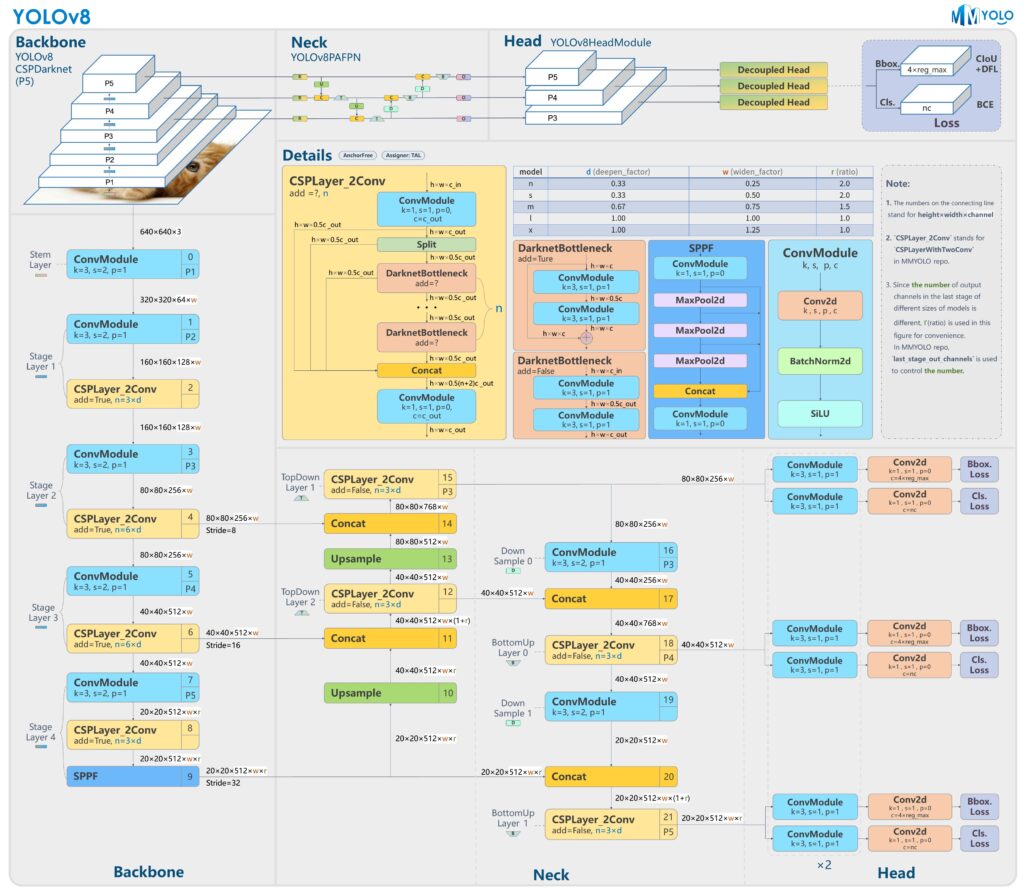
YOLO 的关键特性
单个神经网络进行检测:与传统的目标检测方法通常需要单独生成区域建议和对这些区域进行分类的步骤不同,YOLO 使用单个卷积神经网络 (CNN) 来同时完成这两项任务。这种统一的方法允许它实时处理图像。
速度和实时处理:YOLO 的架构使其能够以极快的速度处理图像,使其适用于需要实时检测的应用,例如视频监控和自动驾驶车辆。
全局上下文理解:YOLO 在训练和测试期间查看整个图像,使其能够以上下文的方式学习和预测。这种全局视角有助于减少目标检测中的误报。
版本演变:最新的迭代,如YOLOv5、YOLOv6、YOLOv7,以及最新的YOLOv8,都引入了重大改进。这些较新的模型专注于通过更多层和先进功能来改进架构,从而增强其在各种现实世界应用中的性能。
对计算机视觉的影响
YOLO 对计算机视觉深度学习领域做出了重大贡献。它能够以实时、准确、高效的方式执行目标检测,为以前受限于较慢检测速度的实际应用开辟了无数可能性。它随着时间的推移而不断发展,也反映了计算机视觉深度学习领域的快速进步和创新。
YOLO 的现实世界应用
交通管理和监控系统:YOLO 模型的一个重要的现实世界应用是在交通管理和监控系统领域。此应用程序展示了该模型能够实时处理视觉数据的能力,这是管理和监控城市交通流量的关键要求。
在交通监控中的实施:车辆和行人检测 - YOLO 用于通过交通摄像头实时检测和跟踪车辆和行人。它能够快速处理视频流,允许立即识别不同类型的车辆、行人,甚至像乱穿马路这样的异常现象。
交通流量分析:通过持续监控交通状况,YOLO 有助于分析交通模式和密度。这些数据可用于优化交通信号灯控制,减少拥堵,改善交通流量。
事故检测和响应:该模型可以检测道路上可能发生的事故或异常事件。在发生事故的情况下,它可以立即提醒相关部门,从而实现更快的紧急响应。
执行交通规则:YOLO 还可以通过检测超速、违规变道或闯红灯等违规行为来帮助执行交通规则。自动出票系统可以与 YOLO 集成,以简化执行程序。
视觉变换器
该模型将最初为自然语言处理设计的变换器的原理应用于图像分类和检测任务。它涉及将图像分割成固定大小的补丁,嵌入这些补丁,添加位置信息,然后将它们馈送到变换器编码器中。
该模型在其架构中使用多头注意力网络和多层感知器的组合来处理这些图像补丁并执行分类。
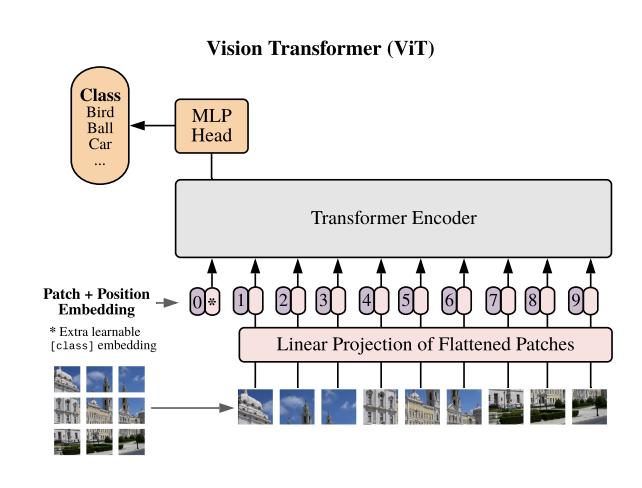
关键特性
基于补丁的图像处理:ViT 将图像分割成补丁并线性嵌入它们,将图像视为一系列补丁。
位置嵌入:为了保持图像部分的空间关系,位置嵌入被添加到补丁嵌入中。
多头注意力机制:它利用多头注意力网络来关注图像中的关键区域,并理解不同补丁之间的关系。
层归一化:此功能通过跨层归一化输入来确保稳定的训练。
多层感知器 (MLP) 头部:ViT 模型的最后阶段,用于对变压器编码器的输出进行分类处理。
类别嵌入:ViT 包含可学习的类别嵌入,增强其准确分类图像的能力。
对计算机视觉的影响
提高准确性和效率:在图像分类方面,ViT 模型已显示出比传统 CNN 显著提高的准确性和计算效率。
适应不同的任务:除了图像分类之外,ViT 在目标检测、图像分割和其他复杂视觉任务中也有效地应用。
可扩展性:基于补丁的方法和注意力机制使 ViT 能够扩展以处理大型复杂图像。
创新方法:通过将变压器架构应用于图像,ViT 代表了机器学习模型感知和处理视觉信息的范式转变。
视觉变压器标志着计算机视觉领域的一次重大进步,为传统 CNN 提供了强大的替代方案,并为更复杂的图像分析技术铺平了道路。
由于视觉变压器 (ViT) 在处理复杂图像数据方面的效率和准确性,它们越来越多地被应用于不同领域的各种现实世界应用中。
现实世界应用
图像分类和目标检测:ViT 在图像分类中非常有效,通过学习图像内错综复杂的模式和关系将图像分类为预定义的类别。在目标检测中,它们不仅对图像中的物体进行分类,而且还精确地定位它们的位置。这使得它们适合于自动驾驶和监控等应用,在这些应用中,对物体的准确检测和定位至关重要。
图像分割:在 图像分割 中,ViT 将图像划分为有意义的片段或区域。它们擅长识别图像中的细微细节,并准确地描绘物体边界。这种能力在医学影像中特别有价值,因为精确的分割可以帮助诊断疾病和状况。



动作识别:ViT 被用于动作识别,以理解和分类视频中的人类动作。它们强大的图像处理能力使其在视频监控和人机交互等领域非常有用。
生成式建模和多模态任务:ViT 在生成式建模和多模态任务中都有应用,包括视觉接地(将文本描述与相应的图像区域关联)、视觉问答和视觉推理。这反映了它们在集成视觉和文本信息以进行全面分析和解释方面的多功能性。
迁移学习:ViT 的一个重要特点是它们具有迁移学习的能力。通过利用在大型数据集上预先训练的模型,ViT 可以针对特定任务进行微调,而只需使用相对较小的数据集。这大大减少了对大量标记数据的需求,使 ViT 适用于各种应用。
工业监控和检查:在实际应用中,DINO 预训练的 ViT 被集成到波士顿动力公司的 Spot 机器人中,用于监控和检查工业场地。该应用展示了 ViT 自动化读取工业过程测量值和采取数据驱动行动的能力,证明了它们在复杂现实世界环境中的实用性。
稳定扩散 V2:关键特性及其对计算机视觉的影响

稳定扩散 V2 的关键特性
先进的文本到图像模型:稳定扩散 V2 融合了强大的文本到图像模型,利用新的文本编码器(OpenCLIP)来增强生成图像的质量。这些模型可以生成分辨率为 512×512 像素和 768×768 像素的图像,与以前的版本相比有了显着改进。
超分辨率上采样器:V2 中一个显着的补充是上采样扩散模型,它可以将图像的分辨率提高 4 倍。此功能允许将低分辨率图像转换为更高分辨率的版本,当与文本到图像模型结合使用时,最高可达 2048×2048 像素或更高。
深度到图像扩散模型:这种被称为 depth2img 的新模型扩展了早期版本的图像到图像功能。它可以推断输入图像的深度,然后使用文本和深度信息生成新的图像。此功能为保持结构的图像到图像和形状条件的图像合成提供了创造性的应用可能性。
增强的修复模型:稳定扩散 V2 包含一个更新的文本引导修复模型,允许智能快速地修改图像的某些部分。这使得用高精度编辑和增强图像变得更容易。
针对可访问性进行了优化:该模型经过优化,可以在单个 GPU 上运行,使其更容易被更广泛的用户使用。这种优化反映了民主化获取先进人工智能技术的承诺。
对计算机视觉的影响
彻底改变图像生成:稳定扩散 V2 在从文本描述生成高质量、高分辨率图像方面的增强功能代表了计算机生成图像领域的飞跃。这为数字艺术、图形设计和内容创作等各个领域开辟了新的途径。
促进创意应用:借助深度到图像和上采样等功能,稳定扩散 V2 能够实现更复杂和更具创造性的应用。艺术家和设计师可以尝试使用深度信息和高分辨率输出,突破数字创意的界限。
改进图像编辑和操作:稳定扩散 V2 的先进修复功能允许更复杂的图像编辑和操作。这在广告等领域可能具有实际应用,因为在这些领域通常需要快速智能地修改图像。
增强可访问性和协作:通过针对单个 GPU 使用进行优化,稳定扩散 V2 可以被更广泛的受众使用。这种民主化可能会导致更多协作和创新的 AI 在视觉任务中的使用,从而促进以社区为中心的 AI 开发方法。
在 AI 中树立新的基准:稳定扩散 V2 将先进功能和可访问性相结合,可能会在 AI 和计算机视觉社区中设定新的标准,鼓励这些领域进一步创新和应用。
现实世界应用
医疗保健和健康教育:健康科技公司 MultiMed 使用稳定扩散技术以多种语言提供可访问且准确的医疗指导和公共卫生教育。
音频转录和图像生成:AudioSonic 项目将音频叙事转换为图像,通过相应的视觉效果增强聆听体验。
室内设计:一个 Web 应用程序利用稳定扩散技术,使个人能够在家庭设计中使用 AI,允许客户快速高效地创建和可视化室内设计。
漫画制作:AI-Comic-Factory 将 Falcon AI 和 SDXL 技术与稳定扩散技术相结合,彻底改变了漫画制作,增强了叙事和视觉效果。
教育摘要工具:Summerize 是一款 Web 应用程序,提供来自在线文章的结构化信息检索和摘要,以及相关图像提示,帮助研究和演示。
游戏中的交互式讲故事:SonicVision 将生成的音乐和动态艺术与讲故事相结合,创造出沉浸式的游戏体验。
烹饪和食谱生成:DishForge 使用稳定扩散技术来可视化食材并根据用户偏好和饮食需求生成个性化食谱。
营销和广告:EvoMate 是一款自主营销代理,它创建针对性的广告系列和内容,利用稳定扩散技术进行内容创作。
播客事实核查和媒体增强:TrueCast 使用 AI 算法在直播播客期间进行实时事实核查和媒体演示。
个人 AI 助理:Shadow AI 和 BlaBlaLand 等项目使用稳定扩散技术来生成相关图像,并创建身临其境的个性化 AI 交互。
3D 冥想和学习平台:3D 冥想和 PhenoVis 等应用程序利用稳定扩散技术来创建身临其境的冥想体验和教育性的 3D 模拟。
AI 在医学教育中的应用:患者模拟器帮助医务人员练习患者互动,使用稳定扩散技术增强沟通和培训。
广告制作效率:ADS AI 旨在通过使用 AI 技术(包括稳定扩散技术)来提高广告制作时间,以创造性地生成产品图像和内容。
创意内容和世界构建:Text2Room 和 The Universe 等平台使用稳定扩散技术来生成 3D 内容和沉浸式游戏世界。
增强在线会议:Baatcheet.AI 使用语音克隆和 AI 生成的背景彻底改变了在线会议,提高了重点和沟通效率。
这些应用展示了稳定扩散 V2 在通过为复杂问题提供创新解决方案来增强各个行业方面的多功能性和潜力。
流行框架 - PyTorch 和 Keras
PyTorch

PyTorch 是由 Facebook 的 AI 研究实验室开发的开源机器学习库。它以其灵活性和易用性而闻名,并且原生支持动态计算图,这使得它特别适合研究和原型设计。PyTorch 还为 GPU 加速提供了强大的支持,这对有效训练大型神经网络至关重要。
查看:Pytorch 入门。
Keras

Keras 现在已集成到 TensorFlow(Google 的 AI 框架)中,是一个高级神经网络 API,旨在简化易用性。最初作为独立项目开发,Keras 专注于通过其用户友好的界面实现快速实验和原型设计。它支持构建深度学习模型所需的所有基本功能,但抽象了许多复杂细节,使其非常适合初学者。
查看:Keras 入门。
这两个框架都在学术和工业环境中被广泛用于各种机器学习和 AI 应用,从简单的回归模型到复杂的深度神经网络。
PyTorch 因其灵活性能常被用于研究和开发,而 Keras 由于其简单性和易用性而被广泛使用,尤其适合初学者。
结论:不断发展的 AI 模型格局
当我们展望 AI 和机器学习的未来时,必须承认,一种模型并不适合所有情况。即使在十年后,我们可能仍然会看到 ResNet 等经典模型与视觉变压器或稳定扩散 V2 等当代模型一起使用。
AI 领域的特点是不断发展和创新。它提醒我们,我们使用的工具和模型必须适应并多样化,以满足不断变化的技术和社会需求。


