
现代计算机视觉 (CV) 和视频分析 (VA) 问题通常通过传统方法和深度学习 (DL) 的结合来解决。深度神经网络推理成为该领域的关键工具,但将其集成到应用程序中并进一步部署有时并非易事——尤其是在算法由多个 DL 网络构建的情况下。此外,当今的硬件平台是异构的,并且可能并行运行应用程序的不同部分。有效地管理此类平台上的复杂工作负载成为一个问题——而 OpenCV G-API 正是为了解决这个问题而生的!本文简要概述了该模块,如何使用它来表达复杂的现代 CV/DL 算法,以及如何从中获得性能。

Dmitry Matveev
英特尔公司软件工程经理
领导 OpenCV G-API 开发并为英特尔物联网事业部 OpenVINO™ 工具包做出贡献
流水线问题
在深入探讨 C++ 中 G-API 编程的细节之前,让我们回顾一下 2020 年典型的视频分析应用程序是什么样的。现代复杂的 CV 工作负载通常计算量很大。一个典型的 CV 应用程序结合了解码、DL 推理、图像预处理和后处理,以及一些自定义应用程序代码或领域逻辑——为了说明这一点,我们将使用 OpenCV、G-API 和 OpenVINO™ 推理引擎构建一个非常基本的“隐私遮蔽”应用程序。
示例:隐私遮蔽流水线
该应用程序的思路很简单:拥有视频流后,识别和保护包含敏感信息的区域——在我们的例子中,可以是人脸和车辆车牌。正在运行的应用程序示例显示在**图 1** 中。

从示意图上看,应用程序数据流可以表示为**图 2** 所示的图形。
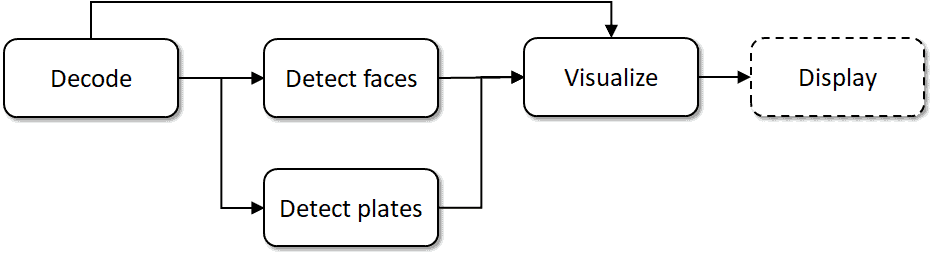
该图由以下节点或步骤组成
- 读取和解码视频流,通过 cv::VideoCapture 完成;
- 使用两个基于 SSD 的网络进行目标检测,由推理引擎评分;
- 自定义 SSD 网络输出处理和可视化代码;
- 在用户界面中显示结果。
在本文的后续部分,我们将分别将这些步骤称为“DEC”、“FD”、“PD”、“VIS”和“DISP”。
在我们的示例中,我们将使用 OpenVINO™ 开放模型库中提供的以下 DL 模型
请注意,第一个网络检测两种类型的对象——车辆和车牌。在我们的示例中,我们只需要处理车牌,因此我们将为此检测器实现自定义处理(过滤)。
朴素执行
如果我们按照我们设想的方式实现此应用程序,那么对于我们处理的每个视频帧,都会得到一个朴素的执行序列,如**图 3** 所示
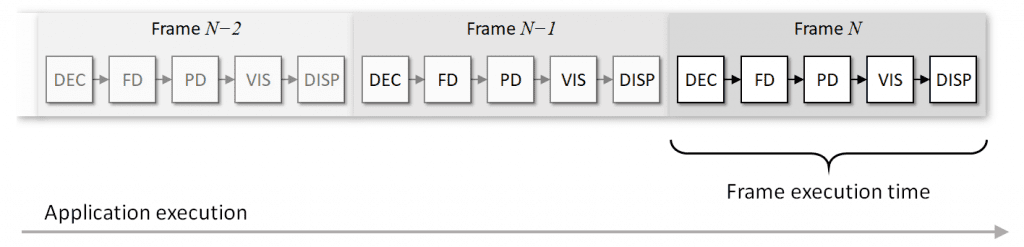
此处,步骤按顺序执行,每个视频帧需要花费~t 时间进行处理,并且每张新输出图像在~t 时间内到达。由于检测到的对象数量可能会有所不同,因此持续时间t 可能会在帧与帧之间略有变化。
流水线执行
显然,上述执行流程远非理想。当今的计算平台通常是异构的,并且可能在机载的不同模块上并行运行。例如,可能存在
- 多核 CPU;
- GPU,集成或独立;
- SoC 上的专用硬件模块,例如用于媒体解码或图像信号处理 (ISP);
- 通过 PCIe 或 USB 连接的额外加速器(例如:Altera® FPGA 卡或 Intel® Movidius™ 神经计算棒)。
在这种情况下,最大化整体应用程序性能需要同时完全加载所有并行计算模块。此技术称为“流水线”;在应用了该技术的示例执行流程显示在**图 4** 中。
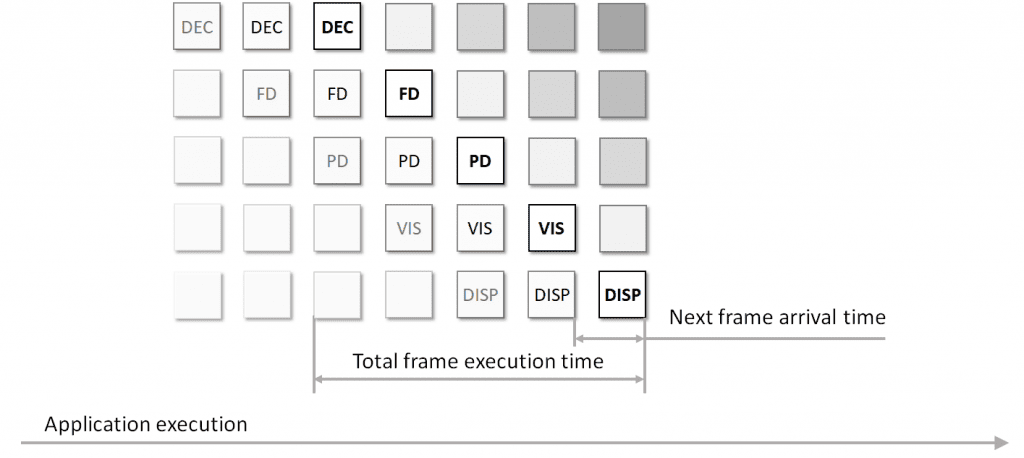
尽管帧处理延迟可能没有真正改变,但与串行模式相比,每个新的处理结果都更快地到达使用者——从而导致更高的整体吞吐量。但是,这假设每个模块确实可以并行运行,并且每个模块的执行时间几乎相同。在现实中,这种情况很少发生——因为系统可能正在处理其他事情,流水线的不同阶段可能需要花费明显不同的时间,并且并行运行的一些阶段可能会影响彼此的性能。
流水线挑战
对于使用 CV 和 DL 进行视频流处理,利用流水线技术看起来是合理的,但我们如何才能使其工作?总有一种方法可以手动进行流水线处理,并自行管理线程、同步和数据流。但是,实施这种方法需要额外的知识,仍然容易出错,并且扩展性不佳。如果算法发生变化,例如我们在流水线中添加了一个新阶段会怎么样?如果我们迁移到另一个具有不同可用选项的平台会怎么样?例如,将推理卸载到外部加速器可能需要同时管理多个异步推理请求。使用手动方法,我们也需要手动更改内容——并且可能需要重复整个调试周期。
解决此问题的一种技术方法是利用计算机机制并自动执行代码流水线的方式。如果我们在算法中进行任何更改或在配置不同的机器上运行它,框架可以在这些更改后自动推断如何调整流水线执行。
现有解决方案
有一些现有的框架可以解决流水线问题,它们各有优缺点——从较低级别的英特尔®线程构建模块库到较高级别的框架,如GStreamer。Khronos® 集团还为基于图形的计算机视觉的 OpenVX™ 标准定义了一个流水线扩展,以解决完全相同的问题。现在,从 4.2 版开始,OpenCV 拥有了自己的东西——OpenCV G-API 已扩展为支持 DL 推理和视频流处理。本文的其余部分解释了 G-API 的核心原理,并说明了此类工作负载如何映射到此新框架。
G-API 简介

G-API(代表“图形 API”)不是一个新的 OpenCV 模块——它于 2018 年在最新的主要 OpenCV 4.0 版本中首次推出。G-API 定位为计算机视觉的下一级优化推动器,专注于整个算法优化,而不是特定的 CV 函数;更多信息请参见这些幻灯片。
G-API 背后的理念是,如果可以用特殊的嵌入式语言(目前为 C++)表达算法,则框架可以捕捉其含义并自动对整个算法应用一系列优化。根据参与图形编译过程的内核和后端选择特定的优化,例如,图形可以通过 OpenCL 后端卸载到 GPU,或使用 Fluid 后端优化内存消耗。内核、后端及其设置是图形编译的参数,因此图形本身不依赖于任何平台特定的细节,可以轻松移植。
编程模型说明
使用 G-API 构建图形很容易。实际上,API 中没有公开图形的概念,因此用户不需要以“节点”和“边”为单位进行操作——相反,图形是通过“函数式”方式隐式地通过表达式构建的。基于表达式的图形使用两个主要概念构建:操作和数据对象。
在 G-API 中,每个图形都以数据对象开始和结束;数据对象传递给操作,操作产生(“返回”)其结果——新的数据对象,然后传递给其他操作,依此类推。程序员可以声明自己的操作,G-API 不会以任何方式区分用户定义的操作与其自己的预定义操作。
定义图形后,需要对其进行编译以供执行。在编译期间,G-API 会确定图形的结构、哪些内核可用于运行图形中的操作、如何管理异构性和优化执行路径。图形编译的结果是一个所谓的“编译”对象。此对象封装了图形内部的执行序列,并对真实图像数据进行操作。程序员可以使用各种编译参数来设置编译过程。后端将其某些选项公开为这些参数;此外,实际的内核和 DL 网络设置也是通过这种方式传递到框架中的。
G-API 支持两种执行模式的图形编译,常规和流式,生成不同类型的编译对象作为结果。
- 常规编译对象由类GCompiled表示,它遵循类似于函子的语义,并具有重载的 operator()。当在给定输入数据上调用执行时,GCompiled 函子会阻塞当前线程并立即处理数据——就像常规 C++ 函数一样。默认情况下,G-API 会尝试在此编译模式下优化延迟执行时间。
- 从 OpenCV 4.2 开始,G-API 还可以生成GStreamingCompiled对象,这些对象更适合异步流水线执行模型。此编译模式称为“流式模式”,G-API 会尝试通过实现如上所述的流水线技术来优化整体吞吐量。我们将在我们的示例中使用两者。
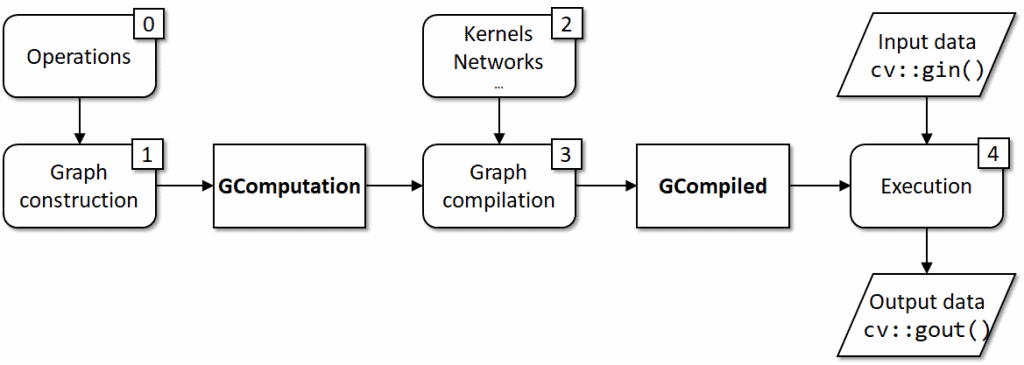
常规情况下的整个过程总结在**图 5** 中。图形由操作构建而成,因此定义操作 (0) 是一个基本先决条件;构建的表达式图形 (1) 形成一个 cv::GComputation 对象;实现操作的内核 (2) 是图形编译 (3) 的基本要求;实际执行 (4) 由 cv::GCompiled 对象处理,该对象接收输入并生成输出数据。
开发工作流程说明
组织 G-API 开发工作流程的方法之一在**图 6** 中给出。
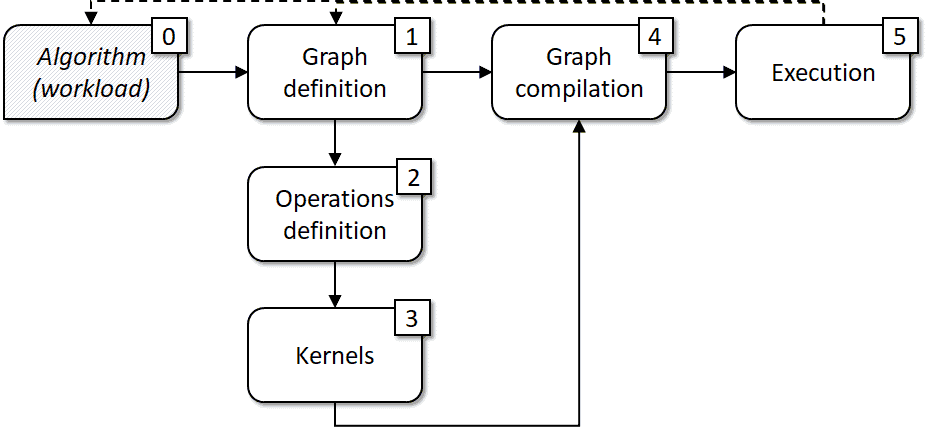
基本上,它派生自上一章(**图 5**)中说明的编程模型。我们首先想到一个算法或数据流(0),将其映射到一个图模型(1),然后识别构建此图所需的运算(2)。这些运算可能已经存在于 G-API 中,也可能不存在,在后者情况下,我们将缺失的运算实现为内核(3)。然后我们决定哪种执行模型更适合我们的情况,将内核和 DL 网络作为参数传递给编译过程(4),最后切换到执行(5)。该过程是迭代的,因此如果我们想根据执行结果更改任何内容,我们可以返回到步骤(0)或(1)(虚线)。
在下一节中,我们将应用此简单过程来使用 G-API 实现我们的示例。
使用 G-API 实现隐私掩码管道
根据所述过程,工作负载实现包括三个步骤
- 将我们的工作负载映射到图结构;
- 识别和实现缺失的部分;
- 配置和运行管道。
本节详细介绍每个步骤。
将工作负载映射到 G-API
现在是时候将我们最初的示例(**图 2**)映射到 G-API 了。我们将使用 OpenCV 的 cv::VideoCapture 访问视频流;G-API 已经附带了 推理 和 渲染 API,我们工作负载中缺少的部分是解析检测输出并将其转换为 G-API 的 Mosaic 原语的函数(在**图 7** 中以橙色突出显示)。

声明网络
在 G-API 中,推理是一个通用(模板)运算,并且使用特殊的宏 G_API_NET 定义特定的网络。
G_API_NET(VehLicDetector, <cv::GMat(cv::GMat)>, "vehicle-license-plate-detector");
G_API_NET(FaceDetector, <cv::GMat(cv::GMat)>, "face-detector");G-API 试图保证类型安全,因此运算和网络实际上是 C++ 类型。在这里,我们声明了两种类型—“VehLicDetector” 和“FaceDetector”,以及它们的调用约定—两者都采用 cv::GMat 输入并产生 cv::GMat 输出。每个宏的第三个参数是一个字符串标识符,G-API 在内部使用它;标识符在单个图的范围内必须唯一。
声明内核
接下来,我们需要将 SSD 格式的检测解析为矩形数组。此运算通常称为“后处理”,因此这是我们的



using GDetections = cv::GArray<cv::Rect>;
G_API_OP(ParseSSD, <GDetections(cv::GMat, cv::GMat, int)>, "custom.privacy_masking.postproc") {
static cv::GArrayDesc outMeta(const cv::GMatDesc &, const cv::GMatDesc &, int) {
return cv::empty_array_desc();
}
};我们的后处理运算采用三个参数—SSD 结果 blob、原始输入图像和一个整数类以过滤掉对象(请记住我们来自 OpenVINO™ Open Model Zoo 的第一个检测器同时检测车辆和车牌)。
最后,我们需要一个运算将我们的检测数据转换为 G-API 渲染原语
using GPrims = cv::GArray<cv::gapi::wip::draw::Prim>;
G_API_OP(ToMosaic, <GPrims(GDetections, GDetections)>, "custom.privacy_masking.to_mosaic") {
static cv::GArrayDesc outMeta(const cv::GArrayDesc &, const cv::GArrayDesc &) {
return cv::empty_array_desc();
}
};请注意,在 OpenCV 4.4 中,渲染功能在“wip”命名空间下声明。这意味着它已经可以工作,但仍在试验阶段,因此 API 可能会在将来的版本中发生变化。
构建管道
现在我们已经定义了所有额外的运算,是时候构建图本身了。它在这里
cv::GMat in;
cv::GMat blob_plates = cv::gapi::infer<custom::VehLicDetector>(in);
cv::GMat blob_faces = cv::gapi::infer<custom::FaceDetector>(in);
// VehLicDetector from Open Model Zoo marks vehicles with label "1" and
// license plates with label "2", filter out license plates only.
cv::GArray<cv::Rect> rc_plates = custom::ParseSSD::on(blob_plates, in, 2);
// Face detector produces faces only so there's no need to filter by label,
// pass "-1".
cv::GArray<cv::Rect> rc_faces = custom::ParseSSD::on(blob_faces, in, -1);
cv::GMat out = cv::gapi::wip::draw::render3ch(in, custom::ToMosaic::on(rc_plates, rc_faces));
cv::GComputation graph(in, out);我们的图从声明一个“空”数据对象“in”开始。请注意,实际上 G-API 数据对象不与任何数据关联,而只是表示存在一些数据—并且这些对象仅用于连接运算。只有在编译并准备好执行时,真实数据才会进入管道。
我们使用“VehLicDetector”和“FaceDetector”类型作为通用函数“cv::gapi::infer<>()”的模板参数。由于这两个网络都使用单个输入定义,因此“infer”的这些专门化也只需要一个参数。
生成的检测传递到我们的第一个自定义运算“ParseSSD”。我们使用 G_API_OP 声明的每个运算类型都有一个静态方法“::on()”,它在图中“触发”运算。此方法是从运算签名使用一些 C++ 模板魔法自动生成的,并且再次严格遵循运算类型。实际上,通过调用“T::on()”,我们将运算“T”应用于输入对象并产生新的输出。
最后,我们将检测转换为绘图原语列表,使用另一个自定义运算“ToMosaic”,并将其作为输入传递给标准“render3ch”运算。在这里,我们在单行中触发两个运算。
生成的图作为对象“graph”捕获。我们在特殊的 cv::GComputation 构造函数重载中指定“in”和“out”数据对象作为开始/结束标记,G-API 跟踪在“in”上调用了哪些运算以生成“out”,动态构建相应的图。如果没有办法从“in”跟踪“out”,或者“out”需要比我们传递的更多输入对象(例如,当图实际上有两个输入但我们只指定了一个时),G-API 会抛出异常。
实现内核
以下是基于 OpenCV 的“ParseSSD”运算的实现。G-API OpenCV 内核使用特殊的宏 GAPI_OCV_KERNEL 声明。此宏的第一个参数是为声明的内核指定的新类型名称,第二个参数是我们实现的运算的类型名称。这表示为“OCVParseSSD 内核实现 ParseSSD 运算”,就像在传统的面向对象编程中一样。
GAPI_OCV_KERNEL(OCVParseSSD, ParseSSD) {
static void run(const cv::Mat &in_ssd_result,
const cv::Mat &in_frame,
const int filter_label,
std::vector<cv::Rect> &out_objects) {
const auto &in_ssd_dims = in_ssd_result.size;
CV_Assert(in_ssd_dims.dims() == 4u);
const int MAX_PROPOSALS = in_ssd_dims[2];
const int OBJECT_SIZE = in_ssd_dims[3];
CV_Assert(OBJECT_SIZE == 7); // fixed SSD object size
const cv::Size upscale = in_frame.size();
const cv::Rect surface({0,0}, upscale);
out_objects.clear();
const float *data = in_ssd_result.ptr<float>();
for (int i = 0; i < MAX_PROPOSALS; i++) {
const float image_id = data[i * OBJECT_SIZE + 0];
const float label = data[i * OBJECT_SIZE + 1];
const float confidence = data[i * OBJECT_SIZE + 2];
const float rc_left = data[i * OBJECT_SIZE + 3];
const float rc_top = data[i * OBJECT_SIZE + 4];
const float rc_right = data[i * OBJECT_SIZE + 5];
const float rc_bottom = data[i * OBJECT_SIZE + 6];
if (image_id < 0.f) {
break; // marks end-of-detections
}
if (confidence < 0.5f) {
continue; // skip objects with low confidence
}
if (filter_label != -1 && static_cast<int>(label) != filter_label) {
continue; // filter out object classes if filter is specified
}
cv::Rect rc; // map relative coordinates to the original image scale
rc.x = static_cast<int>(rc_left * upscale.width);
rc.y = static_cast<int>(rc_top * upscale.height);
rc.width = static_cast<int>(rc_right * upscale.width) - rc.x;
rc.height = static_cast<int>(rc_bottom * upscale.height) - rc.y;
out_objects.emplace_back(rc & surface);
}
}
};“ToMosaic”运算以类似的方式实现—在这里,我们只需要获取矩形数组并将其转换为 Mosaic 绘图原语数组,将每个区域几何体与马赛克块大小对齐
GAPI_OCV_KERNEL(OCVToMosaic, ToMosaic) {
static void run(const std::vector<cv::Rect> &in_plate_rcs,
const std::vector<cv::Rect> &in_face_rcs,
std::vector<cv::gapi::wip::draw::Prim> &out_prims) {
out_prims.clear();
const auto cvt = [](cv::Rect rc) {
// Align the mosaic region to mosaic block size
const int BLOCK_SIZE = 24;
const int dw = BLOCK_SIZE - (rc.width % BLOCK_SIZE);
const int dh = BLOCK_SIZE - (rc.height % BLOCK_SIZE);
rc.width += dw;
rc.height += dh;
rc.x -= dw / 2;
rc.y -= dh / 2;
return cv::gapi::wip::draw::Mosaic{rc, BLOCK_SIZE, 0};
};
for (auto &&rc : in_plate_rcs) { out_prims.emplace_back(cvt(rc)); }
for (auto &&rc : in_face_rcs) { out_prims.emplace_back(cvt(rc)); }
}
};配置管道
完成缺失的部分后,我们终于可以编译和执行我们的图了。现在我们需要做的就是打包我们的编译参数并将其传递给 G-API。
const auto plate_model_path = cmd.get<std::string>("platm");
auto plate_net = cv::gapi::ie::Params<custom::VehLicDetector> {
plate_model_path, // path to topology IR
weights_path(plate_model_path), // path to weights
cmd.get<std::string>("platd"), // device specifier
};
const auto face_model_path = cmd.get<std::string>("facem");
auto face_net = cv::gapi::ie::Params<custom::FaceDetector> {
face_model_path, // path to topology IR
weights_path(face_model_path), // path to weights
cmd.get<std::string>("faced"), // device specifier
};
auto kernels = cv::gapi::kernels< custom::OCVParseSSD
, custom::OCVToMosaic>();
auto networks = cv::gapi::networks(plate_net, face_net);
请注意,这是我们实际引用 OpenVINO™ 推理引擎的唯一地方。G-API 带有一个基于推理引擎的后端用于推理,该后端使用通用结构 cv::gapi::ie::Params<> 配置。此结构专门用于我们使用的每个网络类型,以形成关联网络的参数结构。一些网络需要更多配置,例如,当网络产生多个输出时,在这里我们可以(按名称)映射哪个输出层代表网络返回值元组中的哪个输出。同样,此 API 是类型安全的,并且基于网络的类型签名,如 G_API_NET 中所定义。
执行和结果
在本节中,我们将工作负载在两种不同的模式下运行—传统模式和流式模式—并衡量它在每种模式下的性能。
基线:串行模式
在“串行”模式下,G-API 同步生成图结果,当调用 GCompiled 对象进行执行时。我们使用常规的 compile() 方法编译图,手动读取视频,并手动实现读取/处理/显示循环
cv::Mat in_frame;
cv::VideoCapture cap(input);
cap >> in_frame;
auto exec = graph.compile(cv::descr_of(in_frame),
cv::compile_args(kernels, networks));
do {
exec(in_frame, out_frame);
if (!no_show) {
cv::imshow("Out", out_frame);
cv::waitKey(1);
}
} while (cap.read(in_frame));流式模式
流式执行模式在 G-API 中实现流水线执行模型。流式模式的语义不同,但实际上要简单得多。我们需要做的就是使用 compileStreaming() 而不是常规的 compile() 编译图,然后将输入源指定给生成的管道。最后,我们启动管道并在循环中获取/显示结果,直到流结束
auto pipeline = graph.compileStreaming(cv::compile_args(kernels, networks));
pipeline.setSource(cv::gapi::wip::make_src<cv::gapi::wip::GCaptureSource>(input));
pipeline.start();
while (pipeline.pull(cv::gout(out_frame))) {
if (!no_show) {
cv::imshow("Out", out_frame);
cv::waitKey(1);
}
}完整的示例 源代码 可在 OpenCV Github 存储库中找到。
性能比较
示例的结果性能取决于许多选项
- 哪些设备用于推理以及每个网络的推理精度是什么(CPU/INT8、CPU/FP32、GPU/FP16);
- 是否在屏幕上显示生成的视频流(带/不带 UI);
- 执行模型是什么(串行或流式)。
图 8 总结了在 Intel® Core™ i5-6600 上使用 OpenCV 4.4 和 Intel® Distribution of OpenVINO™ 工具包 2020.4 收集的所有 36 种配置的性能测量结果;GPU 代表集成 Intel® Gen9 HD 显卡
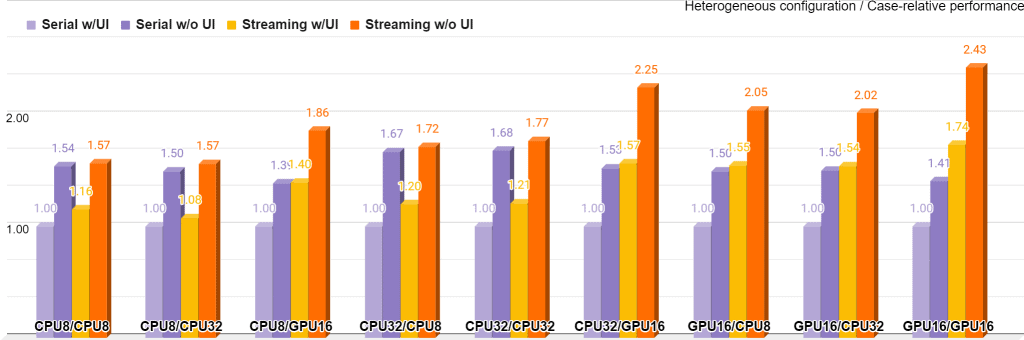
该图表分为九个桶,每个桶代表每个网络的目标+精度对。例如,“CPU8/GPU16”表示 FD 在 CPU 上以 INT8 精度运行,而 LPD 在 GPU 上以 FP16 精度运行。每个桶都以其基线执行模式“Serial w/UI”加权,因此在每个桶中,此模式本身始终为 1.0 标记。在此基础上,每个桶仅显示执行策略如何仅使用给定的 UI 设置提高此特定桶的性能。使用流式模式可以显着提高所有桶的性能,在“GPU16/GPU16”和“CPU32/GPU16”案例中效果最明显。
图 9 从另一个角度展示了这些数据,现在所有测量结果都以“CPU32/CPU32/Serial/UI”基线加权
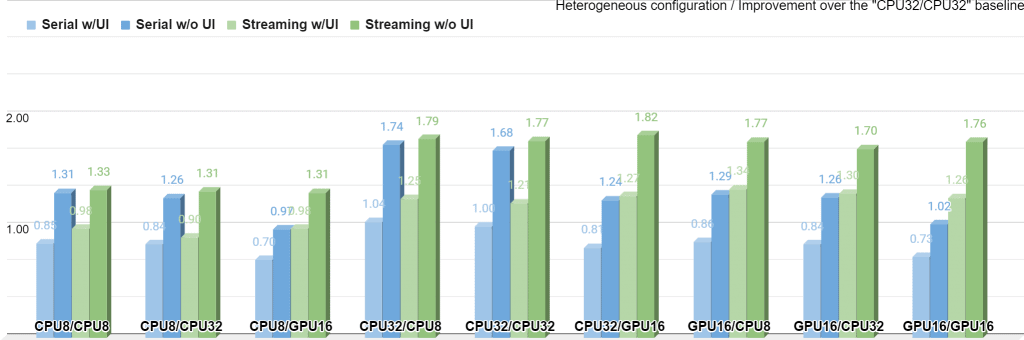
与图 8中的图表相比,此图表反映了系统的整体性能如何随设置而变化。数据仍然像以前一样组织成九个桶,但现在可以合法地将桶相互比较。在“CPU32/GPU16”中,流式模式在没有 UI 的情况下实现了最高的整体性能。
同样清楚的是,在“CPU*/CPU*”案例中,串行和流式性能几乎相同,因为所有管道步骤都开始共享相同的执行资源。但这不适用于“GPU16/GPU16”案例,因为管道仍然包含 CPU 元素(如可视化和解码),并且即使在同一 GPU 上异步执行两个网络也具有性能优势。
结论
流水线是一种强大的技术,可以极大地提高 CV/DL 应用程序的性能。OpenCV G-API 提供了一种技术方法,用于在基于 OpenCV 的用户应用程序中利用流水线,使用紧凑的 C++ 接口来表达流水线,以及引擎盖下复杂的执行引擎。使用此 API,CV/DL 应用程序逻辑与它的运行方式分离,后者变得可配置,并且资源由自动管理。
不过,G-API 中当前的流水线实现还远非理想,但即使在其目前的早期阶段,与串行模式相比,它也提供了显着的额外吞吐量;在未来的 OpenCV 版本中计划对其进行进一步改进。
资源
本文引用了许多在线资源,本节列出了这些资源以方便使用,以及一些其他材料
- GitHub 上的 OpenCV 项目:https://github.com/opencv/opencv
- GitHub 上的 OpenVINO™ Open Model Zoo 项目:https://github.com/opencv/open_model_zoo
- OpenCV G-API 文档:https://docs.opencv.ac.cn/4.4.0/d0/d1e/gapi.html
- OpenCV G-API 教程:https://docs.opencv.ac.cn/4.4.0/df/d7e/tutorial_table_of_content_gapi.html
- OpenCV G-API 幻灯片:https://github.com/opencv/opencv/wiki/files/2020-02-03-GAPI_Overview.pdf
- Khronos® 集团的 OpenVX™ 标准:https://www.khronos.org/registry/OpenVX/
- OpenVX™ 流水线扩展:https://www.khronos.org/registry/OpenVX/extensions/vx_khr_pipelining/1.1/html/vx_khr_pipelining_1_1_0.html
- Intel® 线程构建块:https://www.threadingbuildingblocks.org/intel-tbb-tutorial
- GStreamer 媒体框架:https://gstreamer.freedesktop.org/
本文使用的示例视频为 Bus”,由 sarabernal15 提供,并根据 CC BY-SA 许可证发布。性能测量 脚本 和 示例 本身均为 OpenCV 库的一部分。
法律信息
性能测试中使用的软件和工作负载可能仅针对英特尔微处理器进行了性能优化。性能测试(如 SYSmark 和 MobileMark)是在特定的计算机系统、组件、软件、操作和功能上进行测量的。任何这些因素的更改都可能导致结果发生变化。您应该参考其他信息和性能测试,以帮助您全面评估您计划购买的产品,包括该产品与其他产品结合使用的性能。有关更完整的信息,请访问 www.intel.com/benchmarks。
性能结果基于截至配置所示日期的测试,可能无法反映所有公开可用的安全更新。请参阅备份以获取配置详细信息。没有任何产品或组件可以绝对安全。
英特尔编译器可能针对非英特尔微处理器的优化程度相同或不同,这些优化并非英特尔微处理器独有。这些优化包括 SSE2、SSE3 和 SSSE3 指令集以及其他优化。英特尔不保证任何优化在非英特尔制造的微处理器上的可用性、功能或有效性。此产品中的依赖于微处理器的优化旨在与英特尔微处理器一起使用。某些不特定于英特尔微架构的优化保留给英特尔微处理器。请参阅适用的产品用户和参考指南,以获取有关本通知涵盖的特定指令集的更多信息。通知修订版 #20110804
您的成本和结果可能会有所不同。
英特尔技术可能需要启用硬件、软件或服务激活。
© 英特尔公司。英特尔、英特尔标识和其他英特尔标志是英特尔公司或其子公司的商标。其他名称和品牌可能被认定为其他方的财产。


