
最近发布的目标检测方法在流行的基准测试 - MS COCO 数据集上取得了最先进的性能 (SOTA)。在 第一部分 中,我们仔细研究了 CornerNet。这一次,让我们看看是什么让 CornerNet-Lite 比之前的 CornerNet 方法更出色。

CornerNet-Lite:高效的基于关键点的目标检测
如前所述,CornerNet 的优点是它在 MS COCO 数据集上取得了竞争性的结果。然而,它有一个很大的缺点。
它很慢。
为了克服这个问题,作者提出了 CornerNet-Lite - 两种高效的 CornerNet 变体的组合
- CornerNet-Saccade:它使用注意力机制来避免需要对图像的所有像素进行详尽处理
- CornerNet-Squeeze:它引入了一种新的紧凑型主干网络架构。
这两种方法改进了高效目标检测的两个关键特征:在不牺牲准确性的情况下实现高效率,以及在实时效率下实现高准确率(图 1)。
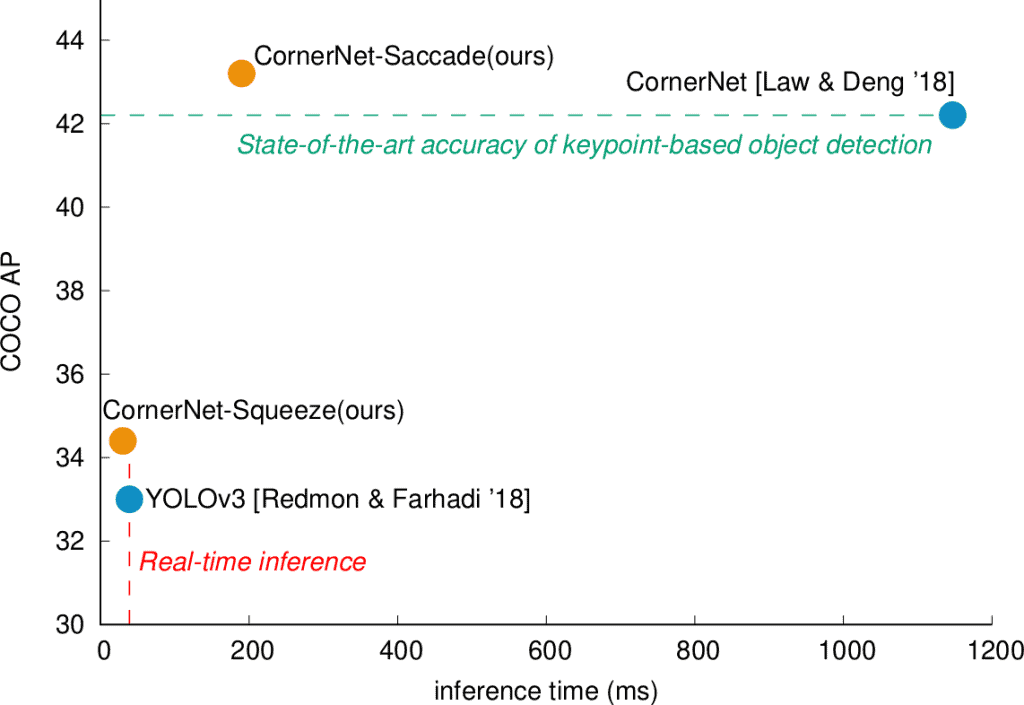
让我们深入探讨这两种新方法,看看它们有什么特别之处。
CornerNet-Saccade:概述
“扫视” 这个词是什么意思?
扫视指的是快速眼球运动,将注视中心从视觉范围的一点快速移动到另一点。扫视主要用于将注视方向指向感兴趣的目标。
该方法的灵感来自于这种自然现象,并由此得名。
下面的图 2 显示了 CornerNet-Saccade 的概述。让我们仔细研究一下。



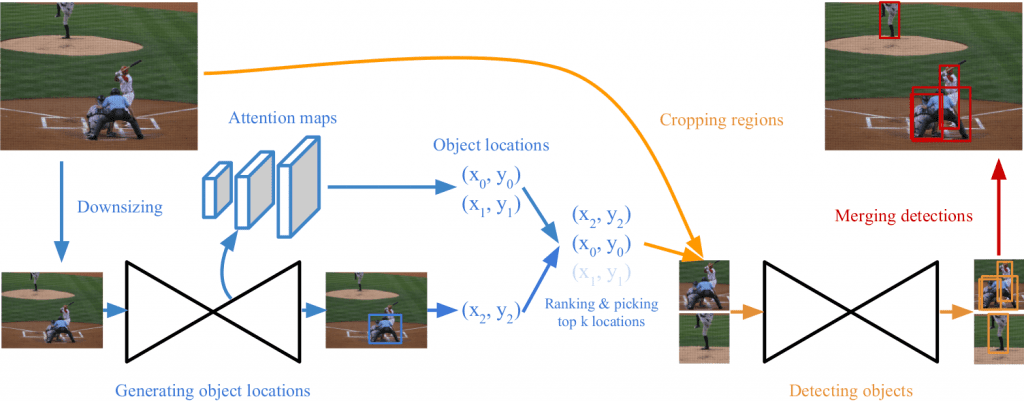
估计目标位置
- 网络对输入图像的两个尺度进行操作。在较高尺度上,图像的长边被调整为 255 像素,在较低尺度上,它被调整为 192 像素。大小为 192 的图像用零填充到 255 的大小,以便可以并行处理这两个尺度。
- 对于缩小的图像,CornerNet-Saccade 预测 3 个注意力图:一个用于小目标,一个用于中等目标,一个用于大目标。
- 注意力图是通过使用从主干网络获得的不同尺度的特征图来预测的,主干网络是一个 沙漏网络。
检测目标
- 从缩小的图像中获得的边界框可能不准确,因此也会在更高分辨率下进行检查,以获得更好的边界框。
- 在每个可能的(x,y)位置,原始图像都会根据目标的大小进行放大,取决于它是小目标、中等目标还是大目标。
- 然后将 CornerNet-Saccade 应用于以该位置为中心的 255×255 窗口,以检测可能的边界框。
合并检测
- Soft-NMS 用于合并和去除冗余边界框。
- 未被区域完全覆盖且与裁剪边界相交的边界框也会被移除,因为它们可能与完整目标的框重叠度很低(图 3)。
- 然后根据检测到的边界框的得分对其进行排名,并只选择得分最高的 k 个边界框。

新主干
建议使用新的 54 层沙漏网络(因此命名为 Hourglass-54)。新架构中的 3 个沙漏模块中的每一个都比 Hourglass-104 中的模块参数更少,而且更浅。
训练细节
- 输入大小:255×255;
- Adam 优化策略;
- 训练超参数与 CornerNet 中相同;
- 在四个 1080Ti GPU 上的批次大小为 48。
CornerNet-Squeeze:概述
让我们继续讨论作者提出的第二种方法,称为 CornerNet-Squeeze。它结合了 SqueezeNet 和 MobileNets 的思想,并通过以下方式减少了处理量
- 使用新的 fire 模块(图 4);
- 沙漏模块修改:
- 降低沙漏模块的最大特征图分辨率;
- 在沙漏模块之前将图像缩小三次,而 CornerNet 将图像缩小两次;
- 用 CornerNet 的预测模块中的 1×1 滤波器替换 3×3 滤波器;
- 用 4×4 转置卷积替换最近邻上采样。

训练细节
论文中提到的某些训练细节
- 训练超参数和损失函数与 CornerNet 中相同;
- 批次大小为 55;
- 4x1080Ti GPU。
结果
图 5 显示了 CornerNet-Saccade 和 CornerNet-Squeeze 在 MS COCO 验证集上的准确率和效率权衡曲线,与其他目标检测器(包括 YOLOv3、RetinaNet 和 CornerNet)进行了比较。
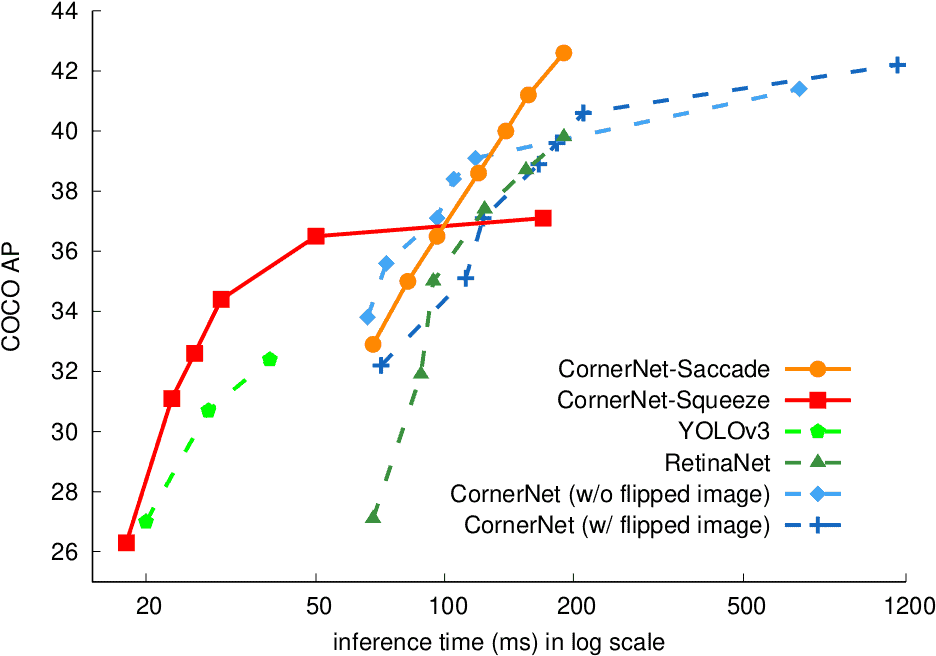
CornerNet-Saccade 在准确率和效率权衡方面(42.6% at 190 ms)优于 RetinaNet(39.8% at 190 ms)和 CornerNet(40.6% at 213 ms)。CornerNet-Squeeze 在准确率和效率权衡方面(34.4% at 30 ms)优于 YOLOv3(32.4% at 39 ms)。在翻转图像和原始图像上运行 CornerNet-Squeeze(测试时增强,TTA)可以将它的 AP 提高到36.5% at 50 ms,但这仍然是一个很好的权衡。
Hourglass-54 的性能分析
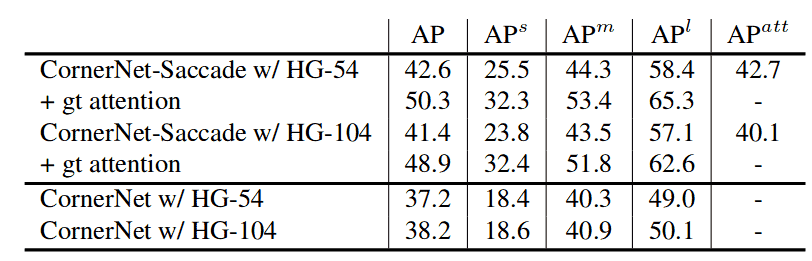
进行了一些实验,以调查新 Hourglass-54 架构对性能的贡献。我们可以看到将预测注意力图作为二元分类问题,其中目标位置为正,其余位置为负。考虑到这一点,作者建议通过平均精度来衡量它的准确性,记为 APatt。Hourglass-54 的 APatt 为42.7%,而 Hourglass-104 的 APatt 为40.1%,表明 Hourglass-54 在预测注意力图方面更出色(图 6)。
CornerNet-Squeeze-Saccade
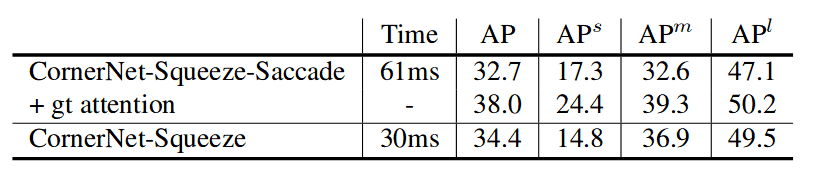
在回顾了这两种方法之后,你可能会想,为什么不将这两种方法合并呢?事实是,一些实验表明,将 CornerNet-Squeeze 与扫视结合起来并不能胜过 CornerNet-Squeeze。
在验证集上,CornerNet-Squeeze 的 AP 为34.4%,而 CornerNet-Squeeze-Saccade 的 AP 为32.7%(图 7)。为了查看扫视如何影响准确性,作者用真实值替换了预测的注意力图。这将 CornerNet-Squeeze-Saccade 的 AP 提高到了38.0%,超过了 CornerNet-Squeeze。结果表明,只有当注意力图足够准确时,扫视才能有所帮助。由于其架构,CornerNet-Squeeze-Saccade 没有足够的容量来同时检测目标和预测准确的注意力图。
CornerNet-Lite 与其他方法在 MS COCO 上的对比
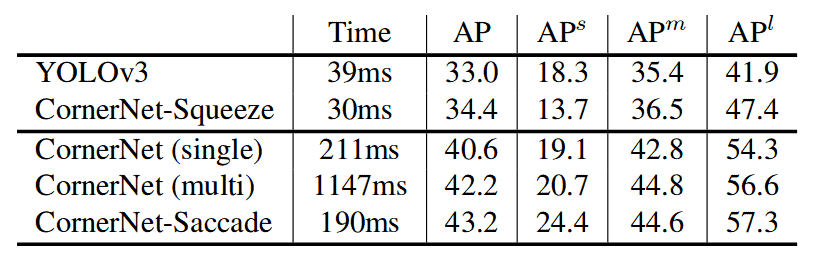
最后但同样重要的是,CornerNet-Lite 在 MS COCO 测试集上的结果(图 8)。CornerNet-Squeeze 比 YOLOv3 更快、更准确。CornerNet-Saccade 在多尺度上比 CornerNet 更准确,速度快 6 倍。这是一项了不起的成就!
CornerNet-Lite 代码
以下是作者公开发布的代码库的链接


