
作者:Alexey Perminov,Tatiana Khanova
我们在之前的博客文章中(PyTorch 和 TensorFlow)已经讨论了几种将您的 DL 模型转换为 OpenVINO 的方法。现在让我们尝试更高级的方法。
当我们开始在应用程序中使用 DL 模型时,我们很快就会发现,DL 模型的预处理和后处理是一个潜在的挑战。在研究阶段,当管道的所有部分都在同一台机器上的同一环境中运行时,一切正常。问题出现在我们将模型集成到解决方案的那一刻。
例如,调整大小操作(以及许多其他操作)可能在不同的平台和不同的库中以略微不同的方式实现,从而导致不同的结果。比 argmax 更复杂的后期处理很可能会被错误地实现。
我们可以通过将所有内容合并到一个计算图中并在 OpenVINO 框架中运行来解决此问题。这样,所有调整大小、规范化和任何后处理都将保持一致并在同一个引擎中运行。我们只需要将输入图像按原样馈送到图中,即可获得所需的结果,我们甚至可以获得加速作为奖励。
选择要转换的模型
在本文中,我们选择了 HRNet 模型(在 用于视觉识别的深度高分辨率表示学习 中提出)。这种相当新的架构已被证明是针对各种计算机视觉任务(如图像分类、目标检测、分割或人体姿态估计)的最先进模型。它在人体姿态估计任务中的应用非常适合我们对预处理和后处理合并的意图。我们将使用 此 来自原始 论文 作者的实现。您还可以在此 博客 中找到更多架构详细信息。
在现代机器学习开发中,我们通常使用一些 DL 框架(TF、PyTorch 等)进行模型设计和训练,但推理框架可能经常不同(OpenVINO、TensorRT)。这种部署过程需要一个或多个不同深度学习模型格式之间的转换阶段,并且所选模型架构可能会对这种转换施加一些限制。这种情况发生在模型包含一些非标准操作(在相当新的论文中提出)时,转换框架尚不支持这些操作。在这种情况下,开发人员要么需要重新设计模型,要么为所选转换器甚至推理后端实现一些自定义操作支持。通常,推理框架会提供这种可能性(并提供非常酷的教程)。幸运的是,HRNet 架构非常有效且足够简单,因此我们不应该遇到这样的障碍。
设置环境
在我们继续之前,我们需要准备和设置环境。过程如下
- 创建一个新的 Python 虚拟环境。
- 安装 OpenVINO 工具包(我们的案例中使用版本 2020.4)。
- 下载准备好的 存储库。
- 从提供的 requirements.txt 中安装 Python 依赖项。
- 下载 COCO 2017 验证集(图像 和 注释)并将它们放置在 “data” 文件夹下,如 Readme.md 中所述。
- 下载模型检查点 (pose_hrnet_w32_256x192.pth) 并将其放置在 “models/pytorch” 路径下。
这里 你可以找到一个 Google Colab 笔记本,其中包含所需的安装步骤以及本文中介绍的复制步骤。
现在我们已经准备好开始。
准备模型进行推理
首先,我们需要一个简单的脚本,用于我们拥有的模型的 PyTorch 推理。我们讨论的所有脚本都位于 “tools” 目录中。让我们看一下基于 test.py 的 pytorch_cpu_inference.py 脚本。
我们使用基于 PyTorch 的数据集加载器和 COCO 数据集绑定来加载图像和进行输入预转换。COCO 2017 验证集总共包含 5000 张图像,但我们只对前 100 张包含人体姿态关键点的图像运行推理,以进行我们的实验。
然后,我们从检查点以评估模式加载模型,并在数据加载器提供的所有输入图像的循环中对其进行推理。对于输出,HRNet 姿势检测模型会为每个关键点类返回热图数组。我们必须对它们进行后处理才能获得检测到的关键点的实际坐标。
最后,我们将调试图像表示保存到文件中,以便我们可以比较结果。在最终的生产部署中,我们通常还需要使用额外的后期处理,如基于对象关键点相似度的非最大值抑制,以消除多余的关键点。我们现在不介绍此阶段,因为这种操作不是严格要求的,因为推理框架目前尚不支持它。
合并预处理
通常,在将图像馈送到模型之前,大多数计算机视觉任务管道都会假设类似的数据预处理步骤,如
- 从输入设备(相机、磁盘、网络)读取图像;
- 颜色方案交换(RGB 到 BGR,反之亦然,或 RGB 到 YUV);
- 将图像调整为模型所需的输入大小(可选);
- 通道顺序交换:NxCxHxW 到 NxHxWxC,反之亦然,其中 N – 批次中图像的数量,C – 颜色通道的数量,H 和 W 分别是图像的高度和宽度;
- 图像数据规范化,包括减去数据集范围内的颜色通道平均值并除以标准偏差值,同样是每个通道。
提议的 HRNet 模型也不例外。数据集绑定以 BGR 格式从磁盘读取图像,然后将它们转换为 RGB 顺序。然后,数据加载器使用 torchvision 的 ‘transforms’ 增强工具集执行图像规范化。让我们将规范化步骤合并到我们的模型中。此带有合并处理的 PyTorch 管道在 pytorch_cpu_inference_merged_processing.py 脚本中定义。
为了合并此预处理规范化,我们需要扩展模型的图,即我们需要编辑模型。幸运的是,我们不需要在之后重新训练模型,因为预处理和后处理操作没有可训练参数。我们定义了新的模型类 PoseHRNetWithProcessing,它继承自 PoseHighResolutionNet,并覆盖了 ‘forward’ 方法(请参阅 lib/models/pose_hrnet.py 以供参考)。
首先,我们定义模型规范化参数
self.mean = torch.FloatTensor([0.485, 0.456, 0.406]) self.std = torch.FloatTensor([0.229, 0.224, 0.225])
然后,在输入数据处理的开头,我们插入相应的规范化处理
x = x - self.mean.view(1, -1, 1, 1) x = x / self.std.view(1, -1, 1, 1)
相应地,我们应该从推理管道中删除此操作,即从数据加载器转换中删除。
合并后处理
正如我们之前提到的,模型输出只是未经处理的热图,它们指定了最有可能的姿势关键点位置,我们必须对它们进行后处理才能获得实际坐标。让我们将此阶段转换为模型计算图的一部分。这是原始管道中后处理的外观,它在 lib/core/inference.py 中定义
def get_max_preds(batch_heatmaps):
'''
get predictions from score maps
heatmaps: numpy.ndarray([batch_size, num_joints, height, width])
'''
assert isinstance(batch_heatmaps, np.ndarray), \
'batch_heatmaps should be numpy.ndarray'
assert batch_heatmaps.ndim == 4, 'batch_images should be 4-ndim'
batch_size = batch_heatmaps.shape[0]
num_joints = batch_heatmaps.shape[1]
width = batch_heatmaps.shape[3]
heatmaps_reshaped = batch_heatmaps.reshape((batch_size, num_joints, -1))
idx = np.argmax(heatmaps_reshaped, 2)
maxvals = np.amax(heatmaps_reshaped, 2)
maxvals = maxvals.reshape((batch_size, num_joints, 1))
idx = idx.reshape((batch_size, num_joints, 1))
preds = np.tile(idx, (1, 1, 2)).astype(np.float32)
preds[:, :, 0] = (preds[:, :, 0]) % width
preds[:, :, 1] = np.floor((preds[:, :, 1]) / width)
pred_mask = np.tile(np.greater(maxvals, 0.0), (1, 1, 2))
pred_mask = pred_mask.astype(np.float32)
preds *= pred_mask
return preds, maxvals
同样,对于预处理,我们使用类似的逻辑扩展了原始模型代码,并在 PyTorch 上对其进行了重写(我们只是将其附加到模型的 ‘forward’ 方法的末尾)
width = x.shape[3]
heatmaps_reshaped = torch.flatten(x, start_dim=2, end_dim=-1)
maxvals, preds_0 = torch.max(heatmaps_reshaped, dim=2, keepdim=True)
preds_0 = preds_0.float()
preds_1 = torch.floor(preds_0 / width)
preds_0 = torch.remainder(preds_0, width)
preds = torch.cat((preds_0, preds_1), dim=2) * torch.gt(maxvals, 0.0)
# x is returned just for the debugging purpose
return x, preds
首先,我们展平热图并提取它们上最大元素的值和位置。然后,我们将位置转换为二维值,并且只保留与正局部最大值对应的那些值。



将模型转换为 ONNX 和中间表示
现在我们有两个用于 PyTorch 推理的管道。现在该转换模型并在 OpenVINO 管道中运行它了。该过程与 之前 相同:我们将模型转换为 ONNX 格式,然后使用模型优化器将其转换为中间表示。
之前准备好的 pytorch_cpu_inference.py 和 pytorch_cpu_inference_merged_processing.py 脚本具有关键的 ‘–convert_onnx’,它允许将相应的 PyTorch 模型转换为 ONNX 格式
if args.convert_onnx:
x_tensor = torch.rand(1, 3, 256, 192)
torch.onnx.export(
model.cpu(),
x_tensor.cpu(),
'model.onnx',
export_params=True,
operator_export_type=torch.onnx.OperatorExportTypes.ONNX,
opset_version=9,
verbose=False)
logger.info('Model is converted to ONNX')
下一步,将其转换为 IR
mo.py --input_model model.onnx
在转换自定义模型时,您可能会遇到与不支持的操作相关的兼容性问题。首先,值得检查包版本和相应的支持层和操作以用于所使用的版本,并升级到最新的可用版本。在这种情况下,我们可以尝试使用另一个版本的 PyTorch,在 torch.onnx.export 调用中使用另一个 onnx 操作集版本,或者使用一个更新的 OpenVINO 版本,如果不是最新的版本。
准备和运行 OpenVINO 推理管道
在此步骤中,我们基于准备好的 PyTorch 推理脚本准备了两个 OpenVINO 推理引擎管道。它们是 openvino_cpu_inference.py 和 openvino_cpu_inference_merged_processing.py。在这些脚本中,我们将 PyTorch 模型加载和推理调用替换为推理引擎初始化,其中包含相应的 IR 模型和同步推理请求。
现在让我们依次运行所有脚本
python tools/pytorch_cpu_inference.py --cfg experiments/coco/hrnet/w32_256x192_adam_lr1e-3.yaml --convert_onnx TEST.MODEL_FILE models/pytorch/pose_hrnet_w32_256x192.pth OUTPUT_DIR pytorch_output
转换生成的 ONNX 模型
mo.py --input_model model.onnx
运行基于 OpenVINO 推理引擎的管道
python tools/openvino_cpu_inference.py --cfg experiments/coco/hrnet/w32_256x192_adam_lr1e-3.yaml TEST.MODEL_FILE ./model.xml OUTPUT_DIR openvino_output
合并处理的模型的相同步骤
python tools/pytorch_cpu_inference_merged_processing.py --cfg experiments/coco/hrnet/w32_256x192_adam_lr1e-3.yaml --convert_onnx TEST.MODEL_FILE models/pytorch/pose_hrnet_w32_256x192.pth OUTPUT_DIR pytorch_w_processing_output mo.py --input_model model_with_processing.onnx --output Conv_746,Mul_772 python tools/openvino_cpu_inference_merged_processing.py --cfg experiments/coco/hrnet/w32_256x192_adam_lr1e-3.yaml -m ./model_with_processing.xml OUTPUT_DIR openvino_w_processing_output
您可以在每个脚本的输出末尾找到打印的平均推理时间。生成的带有关键点和热图的调试图像位于 OUTPUT_DIR 参数指定的文件夹中。
性能比较
您可以在以下图表中找到我们测试设置(CPU:Intel(R) Core(TM) i5-8265U CPU @ 1.60GHz)的结果
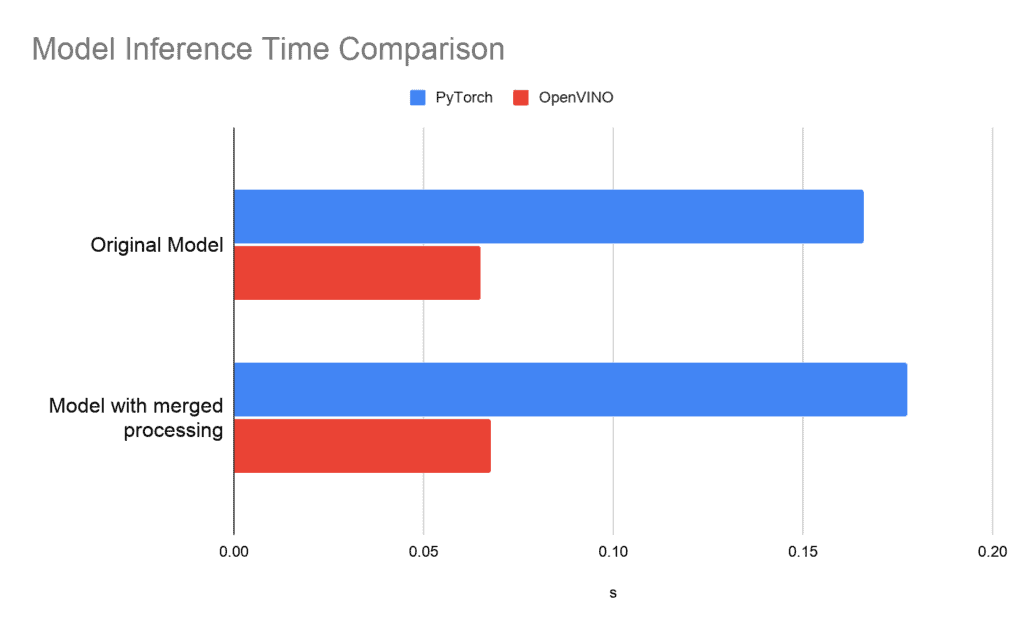
除了相当大的加速之外,我们还可以看到带有合并预处理和后处理的版本只是略微慢,但它具有来自单个计算图的所有优势。
结论
我们已成功将提出的 HRNet 人体姿态估计网络从原始 PyTorch 转换为 OpenVINO 推理引擎管道。此外,我们还研究了如何通过将数据预处理和后处理合并到推理图中来进一步优化推理管道。如上图使用 OpenVINO 工具包的比较图所示,我们实现了显著的推理速度提升,并能够将所有必要的处理步骤合并到单个计算图中,而不会造成任何明显的性能下降。对我来说,最终的结果和计算令人印象深刻,值得尝试在部署到 OpenVINO 推理引擎时使用其他网络进行复制。
________________________________________
获取英特尔® OpenVINO™ 工具包发行版
贡献 – 如果您有任何改进产品的想法,我们欢迎您为开源的 OpenVINO™ 工具包做出贡献。
想了解更多信息?加入对话,在英特尔社区论坛中讨论深度学习和 OpenVINO™ 工具包的一切。
性能会因使用情况、配置和其他因素而异。了解更多信息,请访问 www.Intel.com/PerformanceIndex.
________________________________________
性能结果基于截至配置中显示的日期的测试,可能无法反映所有公开发布的更新。请参阅备份以了解配置详细信息。任何产品或组件都不能绝对安全。
测试日期:2020 年 12 月 23 日
完整的系统配置详细信息:Ubuntu 18.04,英特尔® 酷睿™ i5-8265U CPU @ 1.60GHz x 8
设置详细信息:OpenVINO™ 工具包版本 2020.4
测试人员:Alexey Perminov,OpenCV.AI
英特尔技术可能需要启用硬件、软件或服务激活。
________________________________________
© 英特尔公司。英特尔、英特尔标识和其他英特尔标志是英特尔公司或其子公司的商标。


