
您是否正在寻找一种快速在英特尔平台上运行神经网络推断的方法?那么 OpenVINO 工具包正是您需要的。它提供了大量的优化,允许在 CPU、VPU、集成显卡和 FPGA 上进行闪电般的快速推断。
在之前的 帖子 中,我们了解了如何在 OpenVINO 环境中准备和运行 DNN 模型。今天您将了解有关 DNN 模型优化技术的更多信息。
我们将涵盖以下主题
- 先决条件
- 模型优化器
- 训练后优化工具
- 基准测试工具
- 总结和结论
1. 先决条件
在我们开始之前,请确保您已安装最新版本的 OpenVINO 工具包。为此,您应该使用官方安装说明:这些说明适用于大多数常用平台(Linux、MacOS、Windows)。对于本示例,我们将使用 Ubuntu 18.04。
请确保 OpenVINO 环境已正确初始化。您可以使用以下命令手动执行此操作
source <OPENVINO_INSTALL_DIR>/bin/setupvars.sh
或者,您可以将此命令添加到 bash 初始化脚本
`~/.bashrc` config
因此,每次打开新终端窗口时,环境都会被初始化。
让我们下载并准备模型以进行我们的实验。我们将使用 BlazeFace 和 FaceMesh 的 PyTorch 实现(分别来自 这里 和 这里),这些模型已在之前的 帖子 中转换为 ONNX 格式。但是,OpenVINO 允许我们使用来自其他流行框架(如 TensorFlow、Caffe 或 MxNet)的各种模型。
mkdir -p ~/openvino_optimization/models cd ~/openvino_optimization/models wget link_to_GoogleDrive_blazeface.onnx wget link_to_GoogleDrive_facemesh.onnx
2. 模型优化器
通常,经过训练的 DNN(以及我们之前下载的模型)默认情况下未针对推断进行优化。OpenVINO 工具包提供 模型优化器 - 一个使用静态模型分析来优化目标设备上推断的模型的工具。具体来说,它将一些连续操作融合在一起,以获得更好的性能。
2.1 安装和配置
模型优化器作为 OpenVINO 工具包的一部分部署。它的安装和配置是工具包安装说明的一部分,要配置它,我们只需执行
cd <OPENVINO_INSTALL_DIR>/deployment_tools/model_optimizer/install_prerequisites sudo ./install_prerequisites.sh
请注意,这将全局安装先决条件。为了保持系统清洁,您可能希望在专用环境中初始化它
virtualenv --system-site-packages -p python3 ./venv source ./venv/bin/activate ./install_prerequisites.sh
2.2 将模型转换为中间表示
为了运行模型优化器,我们应该使用位于 <OPENVINO_INSTALL_DIR>/deployment_tools/model_optimizer 目录中的 mo.py 脚本。最简单的方法是将模型文件作为输入提供
python3 mo.py --input_model INPUT_MODEL
模型优化器是高度可配置的。有一组可用于调整转换过程的参数。模型优化器还允许将输入预处理阶段合并到生成的模型中。
- –input_shape: 应馈送到模型的输入节点的输入形状。
- –scale: 来自原始网络输入的所有输入值将除以该值。
- — mean_values: 用于输入图像的每个通道均值。
- –scale_values: 用于输入图像的每个通道缩放值。
- –data_type: 所有中间张量和权重的类型 (FP16、FP32)。
让我们优化我们准备好的 ONNX 模型。
mo.py --input_model ~/openvino_optimization/models/blazeface.onnx --model_name blazeface_fp32 mo.py --input_model ~/openvino_optimization/models/facemesh.onnx --model_name facemesh_fp32
优化结果是为每个模型创建了一个 `.xml` 文件 - 它包含模型架构描述。我们还创建了包含模型权重和偏差的 `.bin` 文件。我们可以将这些文件加载到 OpenVINO 推断引擎中以进行优化推断。
在本示例中,我们的模型在内部具有全精度浮点运算 - 以 FP32 格式。但是,某些设备(如基于英特尔® Movidius™ Myriad™ X VPU 的设备)仅支持 FP16。 这允许在诸如 英特尔神经计算棒 2 或 OpenCV AI Kit 这样的设备上进行高效的神经网络推断。 要将模型部署到类似的边缘设备,请将其转换为 FP16 格式。
mo.py --data_type FP16 --input_model ~/openvino_optimization/models/blazeface.onnx --model_name blazeface_fp16 mo.py --data_type FP16 --input_model ~/openvino_optimization/models/facemesh.onnx --model_name facemesh_fp16
FP 16 或“半精度计算”具有较小的值范围。但是,在许多任务中,范围可能足够好,推断质量将保持不变。并且模型消耗的内存更少。例如,在我们的案例中,FP16 模型权重文件的大小是 FP32 模型权重文件大小的一半。
半精度模型也可能提供更好的性能。但值得注意的是,并非所有硬件架构都支持 FP16。
3. 训练后优化工具
OpenVINO 工具包中部署的另一个优化工具是训练后优化工具 (POT)。它专为不需要重新训练模型的先进深度学习模型优化技术而设计。
3.1 安装和配置
让我们安装 POT。
cd <OPENVINO_INSTALL_DIR>/deployment_tools/tools/post_training_optimization_toolkit python3 setup.py install
这将在 python 环境中部署该工具,并且该工具将通过 pot 别名可用。要验证安装是否成功,您可以运行 pot -h
3.2 在 OpenVino 中进行低精度量化和推断
POT 提供的主要压缩和加速技术是 **统一模型量化**。 它允许使用低精度定点数字(例如,INT8)来近似原始全精度浮点 (FP32) 网络权重。
量化分两个阶段进行
1. **模型量化**。在一些网络层之前添加了特殊的 FakeQuantize 操作以创建量化张量。此阶段的输出是量化模型。量化模型的精度保持不变,量化张量存储在原始精度范围内 (FP32)。
2. **低精度推断**。此阶段由 OpenVINO 推断引擎使用的 CPU 插件 执行。此插件更新 FakeQuantize 层以使用低精度范围内的量化输出张量。它还添加了去量化层以弥补更新。去量化层尽可能地推送到多个层,以便在低精度下具有更多层。之后,大多数层使用低精度范围内的量化输入张量,并且可以在低精度下进行推断。
目前,OpenVINO 推断引擎支持以下层以 INT8 低精度计算模式
- 卷积
- 全连接
- ReLU
- ReLU6
- 重塑
- 置换
- 池化
- 压缩
- 逐元素
- 连接
- 重采样
- MVN
在网络中连续存储的此类层越多(并且可以针对 INT8 推断进行融合),预期的性能提升就越大。
POT 中实现了两种主要且推荐使用的量化算法
- **DefaultQuantization** - 用于获取 8 位量化快速且在大多数情况下准确结果的默认方法。
- **AccuracyAwareQuantization** 允许在量化后保持在预定义的精度下降范围内,以提高性能。精度检查器工具是 OpenVINO 工具包的一部分,用于使用带注释的数据集验证量化过程中的模型精度。
接下来,我们将重点介绍 DefaultQuantization 算法,即使使用未带注释的数据集,我们也可以使用它来执行 INT8 模型量化。



3.3 模型量化
首先,我们需要准备一个将在量化过程中用作输入数据的数据集。从官方 网站 下载对齐的 LFW 数据集,并将所有图像放到单个文件夹中
mkdir -p ~/openvino_optimization/data cd ~/openvino_optimization wget http://vis-www.cs.umass.edu/lfw/lfw-deepfunneled.tgz tar -xzf lfw-deepfunneled.tgz cp ./lfw-deepfunneled/*/*.jpg ./data/. cd ~/openvino_optimization/models
其次,为 POT 准备一个包含量化参数的配置文件。让我们使用默认模板,使用我们模型的信息更新它,并保存为 quantization_spec.json
{
/* Model parameters */
"model": {
"model_name": "blazeface_fp32_int8", // Model name
"model": "blazeface_fp32.xml", // Path to model (.xml format)
"weights": "blazeface_fp32.bin" // Path to weights (.bin format)
},
/* Parameters of the engine used for model inference */
"engine": {
/* Simplified mode */
"type": "simplified",
"data_source": "../data"
},
/* Optimization hyperparameters */
"compression": {
"target_device": "CPU",
"algorithms": [
{
"name": "DefaultQuantization",
"params": {
"preset": "performance",
"stat_subset_size": 300,
"shuffle_data": false
}
}
]
}
}
最后,执行模型量化。生成的模型将保存在 ./optimized 文件夹中
pot -c quantization_spec.json --output-dir . -d
对于第二个模型(FaceMesh),我们只需要更改模型名称和配置文件中的路径,然后重复相同的命令。
我们可以看到,量化后的模型大小与全精度浮点模型相比大幅减小:对于 BlazeFace 为 404kB -> 130kB,对于 FaceMesh 为 2.4MB -> 663kB。
4. 基准测试工具
OpenVINO 工具套件提供了另一种工具——基准测试应用程序,可用于在目标设备上进行快速推理和性能测量。该工具有两种版本:C++ 和 Python。与之前工具一样,我们将继续使用 Python 环境。
4.1 安装和配置
在开始使用基准测试工具之前,我们需要安装 Python 依赖项。
cd <OPENVINO_INSTALL_DIR>/deployment_tools/tools/benchmark_tool/ pip install -r requirements.txt
4.2 运行模型推理
在最简单的情况下,我们只需指定要测量的模型和所需的目標设备即可运行该工具。
python benchmark_app.py -m ~/openvino_optimization/models/blazeface_fp32.xml -d CPU
命令输出将包含所有执行步骤的日志,最后一步将包含性能测量日志。
Count: 7292 iterations Duration: 60055.49 ms Latency: 32.82 ms Throughput: 121.42 FPS
4.3 比较模型性能
正如 所述,为了实现 OpenVINO INT8 量化的优势,我们应该使用至少包含一个 x86 指令集扩展的英特尔硬件:AVX-512、AVX2 或 SSE4.2。在此示例中,以下结果使用的是配备 SSE4.2 指令集的英特尔酷睿 i5-3570K CPU。
让我们比较一下我们转换后的模型的测量结果。
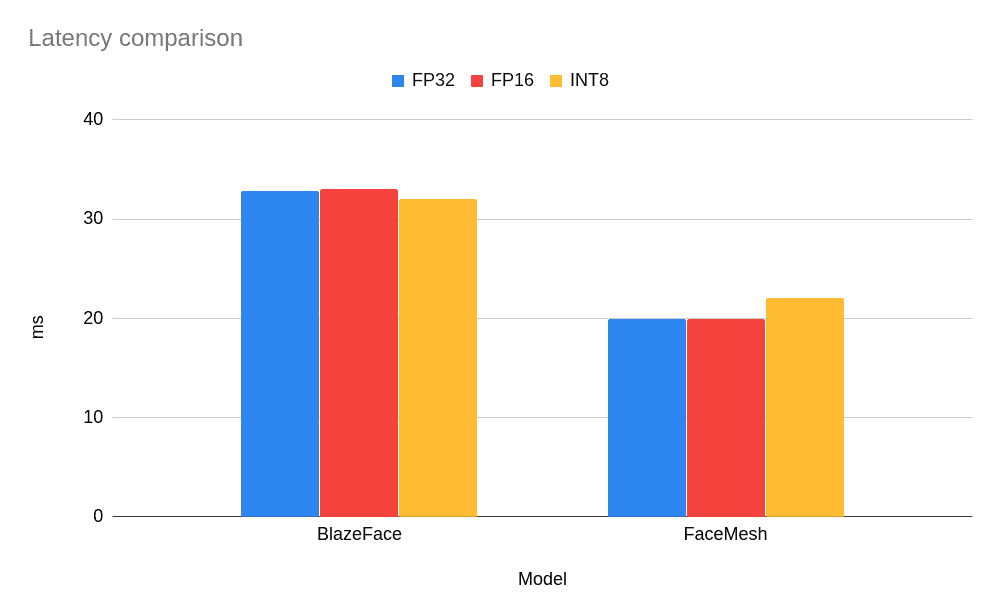
如您所见,对于如此小的模型,没有观察到性能提升,而对于 FaceMesh 模型,低精度 INT8 模型导致延迟略有增加(即,它执行任务的速度更慢)。但是,对于更经典且更大的网络而言,情况如何呢?尤其是那些经过低精度推理验证并在 OpenVINO 开放模型库 中部署的网络?让我们从模型库中获取一个准备好的模型,并比较基准测试结果。以下是基于 MobileNet 主干的 face-detection-adas-0001 模型的结果。
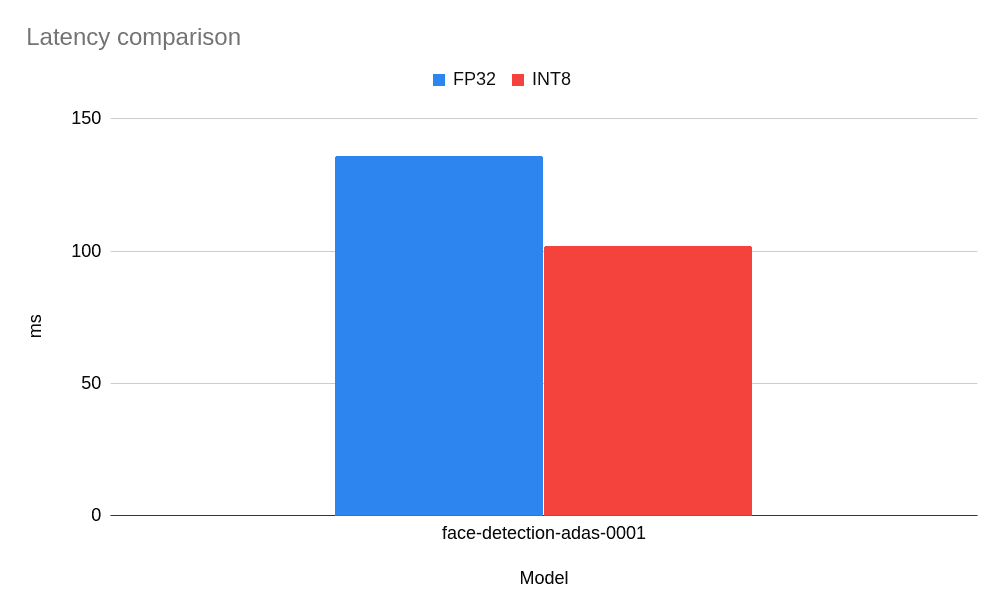
好吧,对于这个模型,我们可以观察到大约 25% 的性能提升。这是一个不错的结果,我们拥有一个提供更快推理的小型模型。
有关英特尔软件产品中性能和优化选择的更多信息,请参阅 https://software.intel.com/articles/optimization-notice。
4.4 比较模型精度
保持足够的精度非常重要,这样应用程序才能继续满足功能要求。让我们从之前的 文章 中获取 OpenVINO 推理管道,看看我们能够实现哪些优化。我们需要用转换为 FP16 和 INT8 格式的模型替换原始模型。
从视觉上看,FP32 和 FP16 模型具有相同的质量,但 INT8 模型通常会提供明显更差的结果。
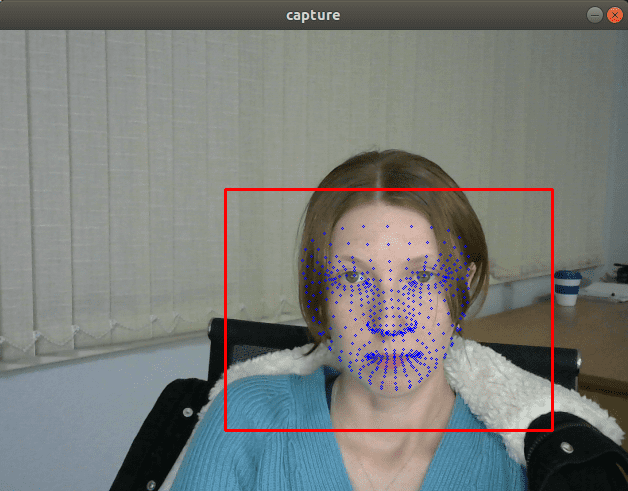
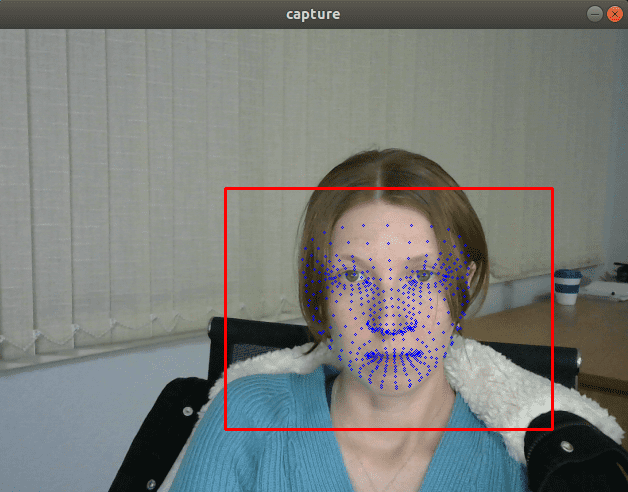
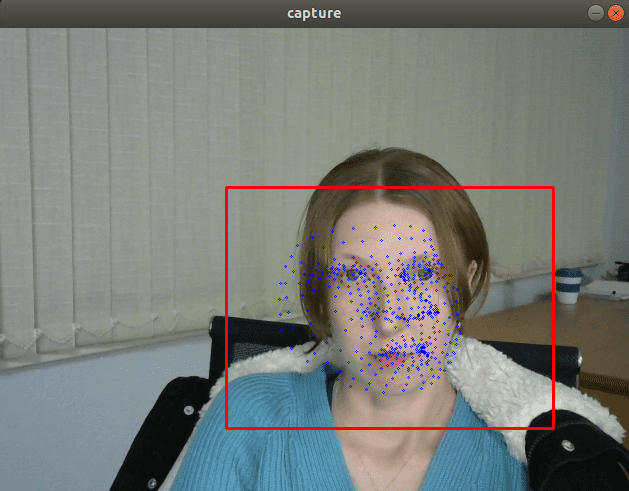
如果我们插入一个打印模型输出的调试跟踪,我们会发现 FP32 和 FP16 模型返回的值几乎相同,但 INT8 模型返回的值可能会因量化误差而相差 10% 以上。
我认为结果在一定程度上是可以预期的,因为我们只是使用了简单的默认量化版本,该版本并非旨在最大程度地提高精度。为了提高 INT8 模型压缩中的精度,我们需要使用 AccuracyAwareQuantization 算法。它需要我们准备一个带注释的数据集,运行量化并检查精度。我将把这种类型的量化排除在本篇文章的范围之外。
5. 总结和结论
我们探讨了 OpenVINO 工具套件中的一些优化 DNN 模型推理执行速度的功能。这些工具允许您在性能和精度之间取得平衡,这些平衡对于您的应用程序至关重要。当然,加速通常会转化为节省成本,并且通常是许多实时交互式应用程序的重要要求。
测试日期:2020 年 9 月 22 日
完整系统配置详细信息:Oracle VM VirtualBox、Ubuntu 18.04.5、英特尔酷睿 i5-3570K CPU @ 3.40GHz × 4
设置详细信息:OpenVINO 工具套件版本 2020.4
测试人员:Alexey Perminov,OpenCV.AI
贡献——如果您有任何改进产品的方法,我们欢迎您为开源的 OpenVINO™ 工具套件做出贡献。
想了解更多?加入英特尔社区论坛的讨论,讨论深度学习和 OpenVINO™ 工具套件的一切。
英特尔致力于尊重人权,并避免参与侵犯人权的行为。请参阅英特尔的 全球人权原则。英特尔的產品和軟體僅供使用於不會造成或促成侵犯國際公認人權行為的應用程式。
英特尔、英特尔标识和其他英特尔商标是英特尔公司或其子公司的商标。
OpenCV 内容合作关系
本文由 OpenCV 团队的一名成员为英特尔撰写,作为 OpenCV 内容合作关系计划的一部分。该计划允许公司赞助与 OpenCV 用户相关的文章。这些文章将与我们的时事通讯订阅者和社交媒体订阅者共享。


