欢迎来到 2050 年!
AI 工具已经失控,没有人再信任它们!这是几乎所有科幻电影的情节。
如果我们不小心,现实可能离这个反乌托邦不远。
幸运的是,我们正在提前思考,并构建工具以安全、合乎道德和负责任地使用 AI。
AI 部署的指导原则需要基于透明度、问责制和公平性。
AI 和 ML 算法无处不在。它们使我们的生活更轻松,减少无聊,提高生产力。我们正在展望一个充满可能性和富足的 AI 驱动的未来。
与此同时,AI 是一把双刃剑。使用不当,它会构成生存威胁。
我们不仅在谈论恶意行为者。我们谈论的是那些想要做好事但没有道德框架来思考他们的 AI 问题的人。
在开发 AI 应用程序时,我们需要确保我们使用默认情况下做出正确和道德选择的工具。
清楚且透明地告知用户其信息如何被收集和使用的工具至关重要。如今,AI 应用程序也越来越多地处理敏感信息,例如聊天记录和浏览器历史记录。
当前的实践(删除、屏蔽等)有助于保护用户数据,但也限制了 AI 模型的开发。
如今的 AI 系统还面临着一个挑战,即在数据本身存在偏差的情况下保持公平。
如何建立一个负责任的 AI 开发流程?
这个流程应该是可重复且可靠的。它应该让团队承担责任,并为审计人员和决策者提供 AI 生命周期的清晰视图。
微软的负责任 ML
在这篇博文中,我们重点介绍了微软的负责任 ML 计划,以及Azure 机器学习及其开源工具包,它提供了一种高效、有效且令人放心的体验。
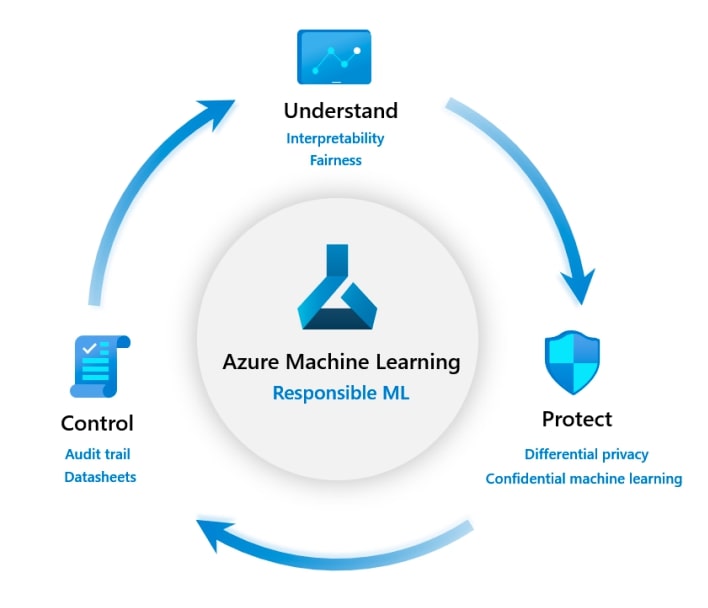
微软的负责任 AI 模型包含三个组成部分:了解、保护和控制 ML 生命周期。



1. 了解模型
这个组件有两个目标。
a. InterpretML
我们生成的 AI 模型不应该是黑盒子。当模型出错时,我们应该知道它为什么这样表现。
这需要了解在训练和推理阶段各种模型的行为。
框架允许进行假设分析,以查看更改特征值如何影响模型预测。
b. Fairlearn
Fairlearn的目标是在保持模型性能的同时,确保模型在训练和部署期间的公平性。它还提供用于交互式可视化的工具,以比较多个模型。
2. 保护数据
机器学习需要大量数据。很多时候,我们可能正在处理敏感或个人数据。因此,我们需要采取措施来维护数据源的隐私。这是通过数据隐私和机密机器学习技术来实现的。
a. 差分隐私,以防止数据泄露
Azure ML 推出了差分隐私工具包WhiteNoise,可与Azure ML一起使用,有助于保护数据源的隐私。
顾名思义,它会向来自不同来源的数据注入噪声,这有助于重新识别数据源。
它还会跟踪对数据源的查询,并防止进一步通信,以降低数据泄露风险。
b. 机密机器学习,以保护数据
机密机器学习是在维护模型训练和部署管道的机密性和安全性方面的过程。
Azure ML 提供了虚拟网络、专用链接以连接到工作区、安全计算服务等工具,以确保您可以控制自己的资产。Azure ML 还允许在不查看数据的情况下构建模型。
3. 控制 ML 流程
可重复性和问责制是训练 ML 模型的重要问题。负责任的 ML 环境需要拥有工具,这些工具可以确保这些因素在训练管道中默认得到考虑。Azure ML 为控制 ML 训练管道提供以下工具。
a. 资产跟踪
Azure ML 提供了用于跟踪资产的工具,例如数据、训练历史记录和环境等。这对于组织来说非常有用,可以帮助他们深入了解模型训练过程,从而获得更多控制权。
b. 使用模型数据表提高问责制
文档是机器学习最重要的方面之一,但往往被忽视。Azure ML 通过数据表提供了一种标准化的方法来记录 ML 生命周期的每个阶段。您可以查看数据表的工作示例这里。
微软还分享了一些负责任 AI 的指南。我们希望更多研究人员和开发人员使用这些工具,以使 ML 的开发和使用更加可靠和值得信赖。
参考资料和进一步阅读
- https://www.microsoft.com/en-us/research/blog/research-collection-responsible-ai/
- https://www.microsoft.com/en-us/ai/responsible-ai
- https://azure.microsoft.com/en-us/services/machine-learning/responsibleml/
- https://azure.microsoft.com/en-us/trial/get-started-machine-learning/
- https://docs.microsoft.com/en-us/azure/machine-learning/
- https://azure.microsoft.com/en-us/services/machine-learning/