

Tony Ng 是 帝国理工学院 MatchLab 的博士生。他的导师是 Dr. Krystian Mikolajczyk,联合导师是 Dr. Vassileios Balntas。他的研究兴趣集中在利用深度学习和经典多视图几何来改进视觉定位。
图像检索是一个长期存在的计算机视觉问题。它被用于图像索引,例如谷歌的图像搜索。它也是许多视觉定位方法的起点。
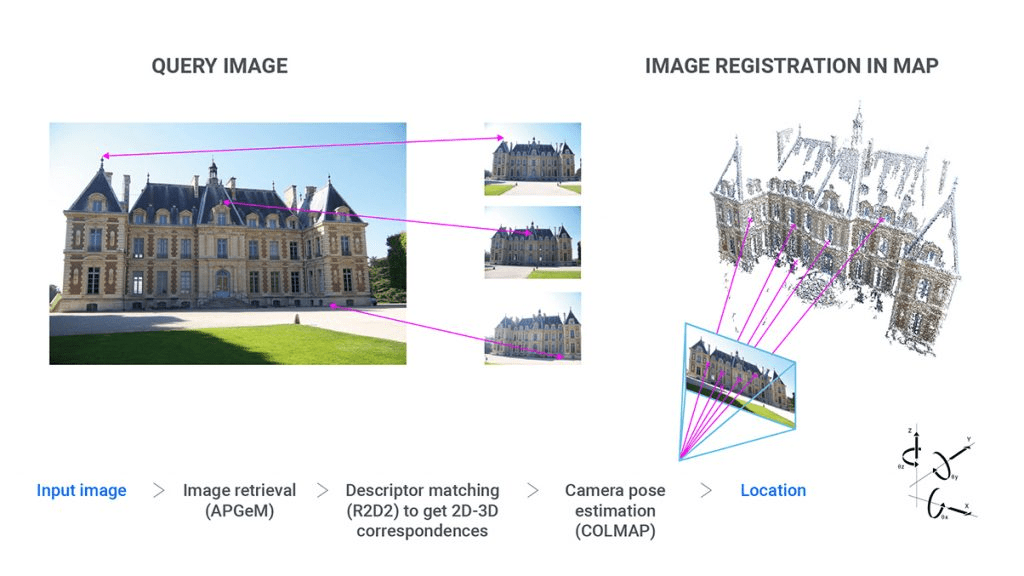
我最喜欢的类比如下:假设你有一块随机的拼图,它属于一百套拼图板 - 视觉定位的目标是将这块拼图 (查询图像的姿态) 放在正确的位置,而图像检索是确定这块拼图实际属于哪套一百个拼图板的第一步。
在这篇博文中,我将首先介绍深度图像检索的最新进展。此外,我将讨论我最近在使用二阶信息和自注意力来改进这些技术的最新工作,以及如何使用 OpenCV 交互式地可视化结果。希望你会觉得它有用!
两种主要的深度图像检索技术类型
为了检索图像,我们必须计算图像之间的相似性。为了有效地对大量图像之间的相似性进行排名,我们首先必须用单个向量表示每个图像,这被称为全局描述符。想想你如何能够非常容易地识别出两个人脸是否是同一个人,即使你以前从未见过这些脸?这是你的大脑天生具备的“描述”脸部的能力,而不必分析脸部的每一个细节。全局描述符在某种程度上与之非常相似,正如其名称所暗示的,以压缩的方式描述图像。事实上,是 这篇著名的脸部识别论文 使 三元组损失 声名大噪,这种损失如今几乎被所有图像检索方法使用!

在深度学习流行之前,图像检索主要是基于局部特征的。局部特征或局部描述符与全局描述符类似,也用向量表示图像。然而,局部描述符只描述图像的一个小区域,这个区域被称为块。由于图像描述的早期工作主要集中在局部描述符上,例如著名的 SIFT,它们通过聚合这些局部描述符来生成全局描述符,例如 词袋模型。
随着深度学习越来越流行,学习到的局部特征也被聚合形成更稳健的全局描述符,由 Arandjelović 等人 和 Noh 等人 的作品开创。我们称这种方法为局部聚合。
深度学习对图像检索的另一个影响是另一类全局描述符,我们称之为全局单次通过。这些描述符依赖于从流行的卷积神经网络 (CNN) 中提取的特征图,例如 AlexNet、VGG、ResNet 等。这本质上类似于聚合局部特征,但使用更简单的数学运算 (例如最大值、中值和平均值),并且得到 GPU 加速器的更广泛支持。因此,全局单次通过方法更具可扩展性 (但通常以准确性和精确度为代价),并且是本文的重点。
全局单次通过描述符的最新进展
随着大量训练数据支持的 CNN 的成功,图像检索界开始认识到 CNN 特征图的潜力。在全局描述符中聚合特征图的早期尝试,即全局池化,包括 最大池化、平均池化。然而,这些特征来自在 ImageNet 上预训练的 CNN,ImageNet 是一个为图像分类而不是图像检索而设计的数据集。 Radenović 等人 的论文是深度图像检索的突破,因为它不仅引入了专门用于 排名损失 的数据集来微调 CNN 用于图像检索,而且还提出了一种更强大的池化操作 - GeM 池化。
这篇论文对我的研究非常重要,因为它不仅是当时的最新方法,而且也是图像检索中最全面的论文之一,它包含大量的实验和结果,为随后对该领域感兴趣的研究人员指明了非常明确的方向。此外,他们的 代码 也写得非常好 (在 GitHub 上有 800 多颗星),我的代码也大量基于他们建立的框架,该框架包括所有模型、数据集训练和评估脚本,这些脚本都是用来重现论文中的结果的。它确实为我节省了数月的宝贵时间!如果你对图像检索感兴趣,我强烈建议你查看他们的存储库。
如果我们有一个输入图像 I $ \in$ IRH, W, з ,在将其通过 CNN 后,我们得到一个特征图 f = $\Theta$ (I) $ \in$ IRh, w, d 。
GeM 池化操作是 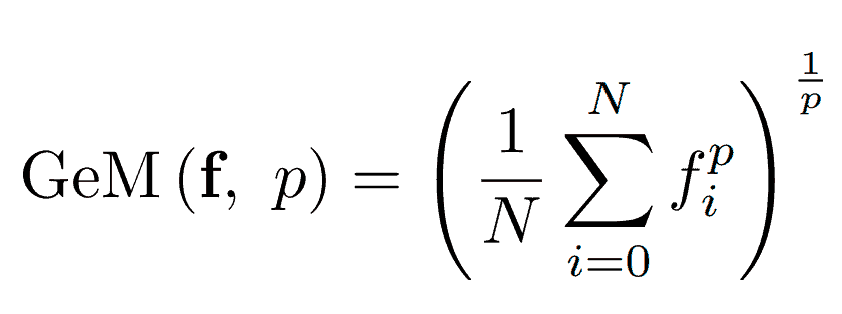
其中 N 是特征的总数,即 N = h x w。
这个公式可能看起来很吓人,但实际上非常直观!简单来说,GeM 取特征图 f 中特征的加权平均值,权重由 CNN 对每个特征的激活来确定。因此,CNN 对某个特征反应越强烈,该特征对全局描述符的贡献就越大。标量 p 然后控制这种加权偏向这些“强”特征的程度。

池化中的二阶信息
对于位置识别和视觉定位,图像检索必须在地标图像上表现良好。与其他领域相比,地标图像呈现出一些独特的挑战。例如,看看图 3,(a) 不同的地标可能看起来非常不同或相似,(b) 一张图像中可能有多个地标,(c) 大部分图像都是无关的,或者 (d) 图像可能是极端条件下拍摄的。

GeM 池化的局限性在于,每个特征只包含其周围空间邻域的信息,因为它是一阶度量。使用图 3 中的 (b) 作为示例,GeM 如何知道圆顶或尖顶更重要?或者两者都很重要?因此,我们需要超越一阶统计量来获得对地标更稳健的全局描述符。
自注意力是自然语言处理中 Transformer 中利用二阶信息的极其成功的机制,在各种计算机视觉任务中也非常流行。图 5 显示了它的工作原理。乍一看它可能看起来非常复杂,但实际上很简单!步骤如下
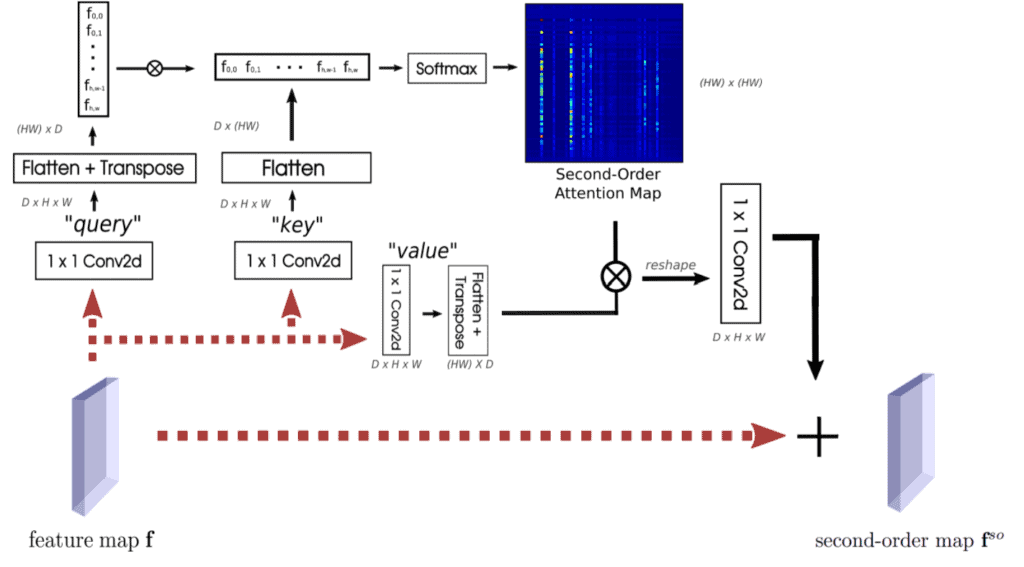
- 还记得之前的特征图 f 吗?我们首先对 f 进行 3 次投影,称为查询 q、键 k 和值 v,所有这些都使用 1×1 卷积。
- 每个 q、k 和 v 都具有与 f 完全相同的形状,即 d x h x w。我们首先在空间维度上将它们全部展平,以获得形状为 d x (hw) 的二维张量。
- 然后我们转置展平后的 q 并与 k 相乘。这里,矩阵乘积 qTk 的形状为 hw x hw。
- 现在我们取此乘积 z = softmax ( $\alpha $ $\cdot $ qTk ) 在其第二个维度上的 softmax。有些人可能已经注意到,这是二阶信息发挥作用的部分。这有效地为 f 中的每个空间位置提供了一个所有空间位置的概率分布!在论文中,我们称 z 为二阶注意力 (SOA)。
- 最后,我们将 z 与 v 相乘,将其重新整形回与 f (d x h x w) 相同的形状,并将其通过另一个 1×1 卷积。然后我们简单地将其添加到 f 中以获得 fso。
你可以将步骤 1-5 视为使用 SOA 重新加权 f 的一种方式。由于 fso 中的每个特征现在还包含来自 f 中所有其他特征的信息,因此对 fso 进行 GeM 池化也应该为我们提供一个对上述地标图像检索挑战更稳健的全局描述符。

让我们尝试通过在地标图像上可视化一些 SOA 来理解它们的效果。在图 5 中,您可以看到,当我们在粉色星号处选择一个空间位置时,该位置对应的 SOA 会叠加在原始图像之上。当粉色星号位于地标内时,SOA 会关注图像中非常独特的部位。当它位于背景/无关物体中时,它会尝试勾勒出图像中主要地标的轮廓。这表明 SOA 能够灵活地调整每个特征从图像其他部位获取信息的程度,从而实现上述的重新加权目标。我们发现,在大型图像检索数据集上,利用 SOA 的二阶信息可以帮助我们获得显著更好的结果,如果您对这个领域感兴趣,我强烈建议您查看我们的 ECCV'20 论文,以获得更深入的分析。



使用 OpenCV 可视化二阶注意力图
在这个项目进行过程中,我不得不不断地在大量图像的不同位置可视化注意力图。最后我得到了一大堆图像和注意力图,我无法从中挑选出合适的示例来研究!幸运的是,OpenCV 允许我们只需点击几下鼠标就可以交互式地选择一个位置,并可视化相应的 SOA。
让我们使用这张埃菲尔铁塔的精美图像,并将其命名为“eiffel.jpg”。

我们可以使用 OpenCV 加载图像。
import cv2
image = cv2.imread("eiffel.jpg")
cv2.namedWindow("image")
# initialize the list of reference points and boolean indicating
refPt = []
现在我们必须创建一个名为 click_and_draw_rect() 的回调函数,它由在 OpenCV 图像窗口上绘制矩形触发。
def click_and_draw_rect(event, x, y, flags, param):
# grab references to the global variables
global refPt
# if the left mouse button was clicked, record the starting
# (x, y) coordinates
if event == cv2.EVENT_LBUTTONDOWN:
refPt = [(x, y)]
# check to see if the left mouse button was released
elif event == cv2.EVENT_LBUTTONUP:
# record the ending (x, y) coordinates and indicate that
refPt.append((x, y))
# draw a rectangle around the region of interest
cv2.rectangle(image, refPt[0], refPt[1], (0, 255, 0), 2)
cv2.imshow("image", image)
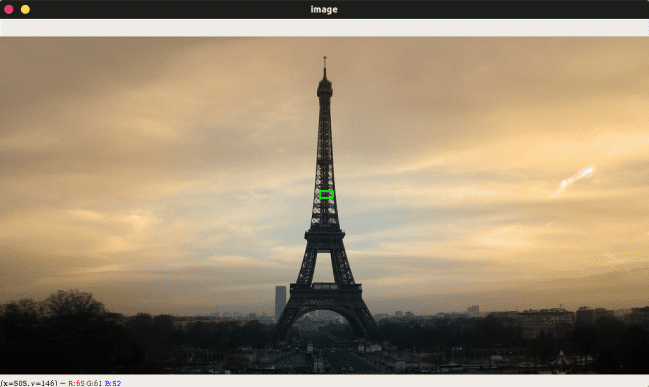
您现在应该在“image”窗口中看到您绘制的(绿色)矩形。现在发生的是, click_and_draw_rect() 记录了三角形对角顶点的坐标,并将它们附加到 refPt 中。
现在,我们想提取这个位置的 SOA。让我们看看这个名为 draw_soa_map(img, model, refPt) 的函数。
import torch
import torch.nn.functional as F
from torchvision import transforms
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.patches import Arrow, Circle
from mpl_toolkits.axes_grid1 import make_axes_locatable
def draw_soa_map(img, model, refPt):
# imagenet statistics for normalization
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
normalize = transforms.Normalize(mean=mean, std=std)
transform = transforms.Compose([
transforms.ToTensor(),
normalize,
])
img_tensor = transform(img).unsqueeze(0).cuda()
fig = plt.figure(dpi=200)
ax = fig.add_subplot(111)
ax.set_xticks([])
ax.set_yticks([])
# h and w are the height and width of our input image
h, w = img_tensor.shape[-2:]
with torch.no_grad():
######################################################
# Here, model (one of the function's arguments) is a torch.nn.Module class, which is our deep CNN. In this case, we are using ResNet-101
# let's say calling model.features(img_tensor) returns two tensors, the first of which is the final feature layer f with size 2048 * h//32 * w//32
# the second of which is the second-order attention map from the last layer with size (h//32 * w//32)**2
#######################################################
f, soa_last = model.features(img_tensor)
# h_last and w_last are the height and width of final feature map f
h_last, w_last = f.shape[-2:]
# now we try to find the location of the centre of the rectangle we drew, i.e. refPt, projected onto f
pos_h_last, pos_w_last = int(((refPt[0][1] + refPt[1][1]) / 2) // 32), int(((refPt[0][0] + refPt[1][0]) / 2) // 32)
# and the location of the original image
pos_h, pos_w = ((refPt[0][1] + refPt[1][1]) / 2), ((refPt[0][0] + refPt[1][0]) / 2)
# then we retrieve the SOA at that location
soa_last = soa_last.view(1, h_last, w_last, -1)
self_soa_last = soa_last[:, pos_h_last, pos_w_last, ...].view(-1, h_m1, w_m1)
self_soa_last = F.interpolate(self_soa_last.unsqueeze(1), size=(h, w), mode='bilinear').squeeze()
# overlay the attention on the original image with alpha mask
ax.imshow(img)
ax.imshow(self_soa_m1.cpu().numpy(), cmap='jet', alpha=.65)
# add a circle at the centre of the rectangle we draw to indicate where the soa is selected from
ax.add_patch(Circle((pos_w1, pos_h1), radius=5, color='white', edgecolor='white', linewidth=5))
plt.tight_layout()
# redraw the canvas
fig.canvas.draw()
# convert canvas to image
img_cv2 = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
img_cv2 = img_cv2.reshape(fig.canvas.get_width_height()[::-1] + (3,))
# img_cv2 is rgb, convert to opencv's default bgr
img_cv2 = cv2.cvtColor(img_cv2,cv2.COLOR_RGB2BGR)
return img_cv2
我知道,这个函数很长很复杂!但是,它所做的只是找到我们在特征图 f 上应该选择的正确位置。由于大多数 CNN(在本例中为 ResNet-101)的最后一个特征图比原始图像具有更低的空间分辨率,因此我们必须除以尺度差并四舍五入原始图像中矩形中心的坐标到特征图的大小(在 ResNet-101 的情况下,f 是输入图像大小的 1/32)。请记住,我们之前提到过 soa 的形状是 hw x hw?在上面的函数中,我们将其重塑为 h x w x h x w ,并使用我们从参考点计算出的 pos_h_last, pos_w_last ,我们可以获得该位置的 SOA,其形状为 h x w。非常简单!
最后,我们在前面的鼠标回调函数之后调用此函数,它仍然在 while 循环内。
from PIL import Image
# if there are two reference points, then crop the region of interest
# from the image and display it
if len(refPt) == 2:
# display soa
soa = draw_soa_map(Image.open("eiffel.jpg"), model, refPt)
cv2.imshow("Second order attention", soa)
cv2.waitKey(20)
# close all open windows
cv2.destroyAllWindows()
(注意:model 是我们使用的 CNN 的 torch.nn.Module 类。有关更多详细信息,请参见 我们的 GitHub 库。)
您应该会看到 SOA 在一个新窗口中弹出。
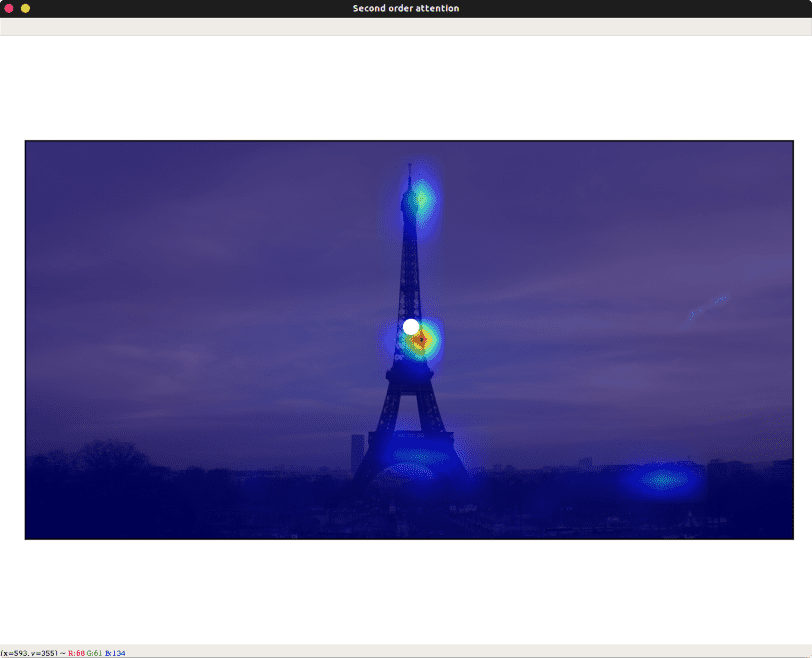
现在尝试在原始窗口的天空上绘制矩形。
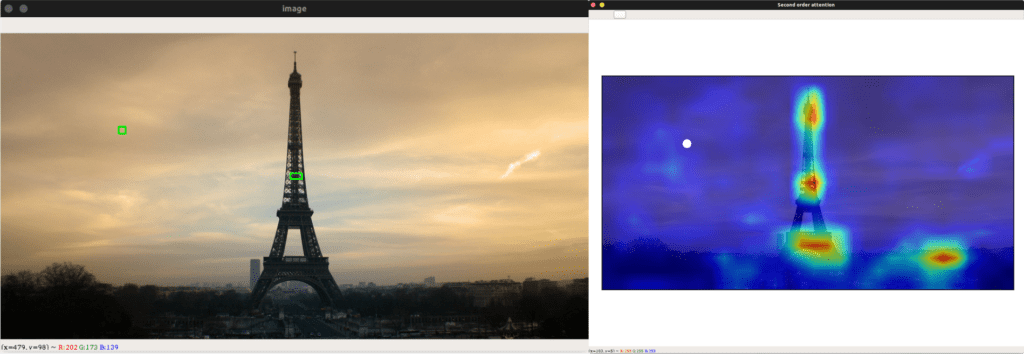
SOA 更加分散,并且勾勒出图像中的地标,这证实了我们之前的观察结果!
借助 OpenCV 提供的此功能,我可以毫不费力地创建 GIF,这非常适合在社交媒体上宣传您的作品!
结论
尽管深度学习对图像检索贡献巨大,但最先进的地标检索技术仍然远非完美。局部聚合方法的准确性和全局单次遍历方法的效率之间存在着不断的拉锯战。我希望我的工作能够略微弥合这一差距,我们能够看到未来出现一些真正令人惊叹的作品,这些作品既快速又准确,能够在极大规模上运行——也许可以在眨眼之间检索数十亿张图像!


